Earlier chapters of this book argued that enterprise architecture must shift from periodic documents to continuous, semantic, executable knowledge. This chapter defines the form that shift takes in practice.
The Enterprise Architecture Codex is the structured embodiment of an enterprise’s collective architectural knowledge: the principles, standards, reference architectures, and blueprints that mature EA practice has always produced, expressed as typed objects rather than documents, governed in Git, and distributed as composable skills that AI assistants can load on demand.
1. From vibes to codex
The phrase that captures the underlying shift came from a developer who put it bluntly: “the problem was my prompts were vibes, not specifications.” That observation reflects something larger than a personal coding habit. It reflects a change taking place across engineering and architecture practices. Enterprises are moving from intuition-driven prompting, where an architect or engineer types a question into an AI assistant and hopes the model fills in the missing context, to specification-driven work, where the intent, the constraints, and the expected outcome are explicit before any generation begins.
Agentic AI accelerates this evolution because agents do more than answer questions. They make changes. They write code, modify configurations, propose pull requests, and trigger workflows. When an agent acts on vibes, the consequences propagate through delivery systems faster than humans can correct them. When an agent acts on a specification anchored in shared enterprise knowledge, the same speed becomes an asset rather than a risk.
The Enterprise Architecture Codex is the form in which that shared knowledge becomes usable to both humans and machines.
It is not a documentation portal, not a wiki, and not a vendor product. It is the structured embodiment of the practices, constraints, principles, and approved ways of working that the enterprise has agreed on, organized so that AI assistants can activate the right chapters of it depending on what is being done and where in the lifecycle it is being done:
- A data engineer building a pipeline activates one set of Codex chapters.
- A solution architect designing an integration activates a different set.
- A compliance reviewer auditing an AI agent activates yet another.
The Codex does not replace the prompt; it shapes the context around the prompt so that the AI’s output remains aligned with what the enterprise has already decided.
Seen this way, the Codex is closer to organizational memory than to documentation. A document captures what someone wrote at a moment in time. The Codex captures what the enterprise has agreed to be true, in a form that survives the people who wrote it and the systems that originally hosted it. It evolves as the enterprise evolves. And because it is structured rather than narrative, the same content can be read by an architect during a review, loaded by an AI assistant during a generation, queried by a compliance engine during an audit, and referenced by a delivery pipeline during a deployment, without anyone having to translate it between forms.
This chapter addresses the operational question that follows. Once architectural knowledge is treated this way, what concrete form does it take, how is it organized, how is it distributed, and how is it governed in a way that does not collapse back into the document-centered habits it was meant to replace?
The answer this chapter develops draws on a working configuration: the Codex packaged as a set of composable skills, stored in a Git repository, distributed through marketplace-style channels into AI clients such as Claude Desktop, Claude Code, and the Claude API, and governed through the same merge-request discipline that engineering practice has spent two decades developing for source code.
2. The four building blocks every EA practice already produces
Before describing how the Codex changes the form of architectural knowledge, it is worth being explicit about what that knowledge actually is. Mature EA practice produces four kinds of object. They appear under slightly different names in different methods, but the underlying concepts are stable, and TOGAF’s Architecture Content Framework names all four as foundational architecture building blocks. The Codex does not invent a new vocabulary. It changes how each of these objects is carried.
2.1. Architecture principles
A principle is a normative statement about how the enterprise expects technology decisions to be made. TOGAF defines it as a general rule and guideline, intended to be enduring and seldom amended, that informs and supports the way an organization sets about fulfilling its mission.
A principle has four conventional parts: a statement, a rationale, the implications it produces for delivery, and the conditions under which it applies.
Examples include “applications must be cloud-first unless a specific exception applies”, “AI agents operating in regulated contexts must have an explicit human review route”, and “data classified as personal must remain in approved jurisdictions”.
Principles answer the question of what the enterprise expects of any solution, regardless of which specific solution is being built.
2.2. Technology standards
A standard names what the enterprise considers approved, restricted, or deprecated for a given category of technology. TOGAF treats standards as one of the principal forms of governance over technology choice. Where a principle states intent, a standard states the concrete instances that satisfy or violate that intent.
A standards catalog typically includes the technology category, the approved instances, the radar position (adopt, trial, observe, hold, retire), the applicability scope, and the exception process.
A radar entry for a database technology might say “PostgreSQL 14 or later, approved, applies to all transactional workloads handling personal data, exceptions require a CISO review”.
Standards answer the question of which specific technologies and patterns the enterprise will use to realize its principles.
2.3. Reference architectures
A reference architecture is a reusable structural pattern that solves a recurring problem within a domain. TOGAF distinguishes between architecture building blocks and solution building blocks; reference architectures sit between them, capturing the structural commitments that any concrete solution must respect while leaving the implementation choices to delivery.
A reference architecture has layers, components, relationships, and invariants. The reference architecture for an AI agent might define a four-layer structure (governance, orchestration, agent, data) with required components in each layer and typed relationships that bind the agent’s actions to policy enforcement.
Reference architectures answer the question of how a class of system should be structured.
2.4. Blueprints and target-state architectures
A blueprint expresses where a transformation is going and how it will get there. TOGAF treats target-state architectures and transformation roadmaps as distinct artifacts, but in most enterprise practice they are produced and consumed together.
A blueprint includes the target state, the transitions between current and target, the dependencies between transitions, the timeline, and the KPIs that mark success. A blueprint for the rollout of an AI agent across regions defines the controlled pilot, the staged extension, the scale operations phase, and the conditions that gate progress between them. Blueprints answer the question of how the enterprise gets from its current state to its target state.
2.5. Synthesis
These four objects are stable. What changes between enterprises is not whether they exist but how seriously they govern delivery. In some organizations:
- The principles document was last updated three years ago and is rarely cited in practice.
- The standards catalog is a wiki page that has drifted out of sync with what teams deploy.
- Reference architectures circulate as PDFs whose authors have left the company.
- Blueprints are slide decks that survived a steering committee but never connected to anything that builds.
The enterprise has the right vocabulary and the wrong artifacts.
3. The business-domain knowledge that sits beneath the four building blocks
The four TOGAF building blocks are the visible output of EA practice, but they do not float in a vacuum. They anchor to a layer of business-domain knowledge that tells the Codex what the enterprise is, which capabilities it runs, what intent drives its transformation agenda, what its semantic vocabulary means, and who in the organization owns what:
- A principle about human-in-the-loop escalation is meaningless without a capability to bind it to.
- A standard for a policy engine is inert without a business function that needs governance.
- A reference architecture for an AI agent cannot be evaluated without the enterprise intent it is meant to serve.
The Codex therefore holds not just the TOGAF building blocks but the semantic substrate beneath them.
3.1. Business capability maps
A capability names a unit of business function (Adverse Event Intake, Customer Onboarding, Supply Chain Planning, Regulatory Submission Preparation) independent of the applications that support it.
Capabilities are more stable than applications and less abstract than principles, which is why they are the anchor point that most other Codex objects reference.
In the EA tool, capabilities are typed fact sheets; Codex artifacts reference them via eatool:bc.<domain>.<name> identifiers and treat them as the applicability scope that principles name, the deployment target that standards name, the function that reference architectures name, and the transformation subject that blueprints name.
The fragment below is CAP-PV-001 (Adverse Event Intake), the capability the ACME Pharma pharmacovigilance scenario runs through. Note the two features that distinguish it from a capability name on a slide:
- The regulatoryAnchors field ties the capability to external obligations that constrain its design
- The supportedBy field anchors it to actual applications (Figure 1 below) in the portfolio so that coverage gaps and redundancies can be computed rather than narrated.
# EA tool BusinessCapability fact sheet (LeanIX, Ardoq, ServiceNow, or equivalent).
# Per ea.codex/v1.1.0, BusinessCapability is not a typed Codex kind; capabilities
# are referenced from Codex artifacts as eatool:bc.<domain>.<name> identifiers.
# The rich content shown here lives in the EA tool's catalogue.
factSheetType: BusinessCapability
metadata:
id: eatool:bc.pv.adverse-event-intake
displayId: CAP-PV-001
name: Adverse Event Intake
domain: Pharmacovigilance
owner: global-safety-function
criticality: high
capability:
description: >
Receive, classify, and route adverse-event information from
multiple channels (email, call center, web form, partner reports)
into the pharmacovigilance case-management lifecycle.
maturity: defined
parent: CAP-PV-000 # Pharmacovigilance (parent domain)
children:
- CAP-PV-001-01 # Multi-channel reception
- CAP-PV-001-02 # AI-assisted triage
- CAP-PV-001-03 # Case creation handoff
regulatoryAnchors:
- framework: EMA GVP Module VI
obligation: timely receipt and validity assessment of ICSRs
- framework: FDA 21 CFR 314.80
obligation: postmarketing adverse drug experience reporting
- framework: PMDA GVP Ordinance
obligation: timely reporting for Japan market
supportedBy:
- application: aiTriageService
coverage: AI-assisted triage
- application: pharmacovigilancePlatform
coverage: case lifecycle, system of record
- application: customerInteractionPlatform
coverage: intake channel
valueStream:
role: intake-gate
upstream: patient / reporter / partner / call-center
downstream: CAP-PV-002 (Safety Case Normalization)
linkedIntent:
- INTENT-PV-001
linkedPrinciples:
- AI-005
- DATA-003
linkedReferenceArchitectures:
- REF-AIAGENT-001
owningCouncilMember: pharmacovigilance-domain-leadFigure 1: BusinessCapability fact sheet for Adverse Event Intake (eatool:bc.pv.adverse-event-intake).
The capability is the piece of enterprise context that lets a general principle land on a specific application with the right weight:
- AI-005 (Human-in-the-Loop Escalation) targets AI agents as its applicability scope.
- The aiTriageService fact sheet says it supports CAP-PV-001.
- CAP-PV-001’s regulatoryAnchors say that EMA GVP Module VI, FDA 21 CFR 314.80, and PMDA GVP Ordinance govern adverse-event intake.
From this chain, the compliance engine derives that the AI Triage Service operates in a regulated adverse-event context, and that AI-005’s human-review-route requirement is therefore a hard constraint rather than a soft recommendation.
Without the capability map, the principle either misses the application (because nothing tells the engine that “aiAgent category in pharmacovigilance” means anything specific) or over-applies (because the engine has no way to distinguish regulated from non-regulated contexts).
3.2. Enterprise intent
Chapter 3 introduced intent as a structured typed object, INTENT-PV-001 being the specific example for pharmacovigilance.
In the Codex, intent lives alongside capabilities, not above them.
A single strategic intent may touch multiple capabilities (accelerating adverse-event intake affects CAP-PV-001 for reception, CAP-PV-002 for normalization, and CAP-PV-003 for medical review).
The Codex tracks those links so that downstream architectural decisions can cite their intent anchor and so that intent evolution (the strategic priority changes, a new regulatory framework comes into force, a new acquisition expands scope) ripples automatically through the decisions, specifications, and blueprints that depend on it.
This is what distinguishes the Codex treatment of intent from an intent statement in a slide deck: the Codex intent is traversable, so the consequences of changing it are visible before anyone acts on the change.
3.3. Semantic glossary and ontology
The vocabulary an enterprise uses is usually inconsistent across business units.
- “Customer” means different things to the commercial team, the legal team, the risk team, and the finance team.
- “Adverse event” has a precise regulatory meaning in pharmacovigilance that differs from colloquial usage.
The Codex carries an ontology skill that resolves these ambiguities with typed term definitions, synonym mappings, scope boundaries, and cross-references to the Enterprise Architecture objects they align to. When AI-assisted tools generate architectural content, they read from this ontology so that “customer” in an AI agent’s generated output means what the enterprise has agreed it means, not whatever the model’s training distribution inferred.
The ontology is what prevents the Codex from producing fluent but semantically wrong content, which is the failure mode that structured prompting without shared vocabulary cannot escape.
3.4. Organizational model
The EA Council from Chapter 4 is a first-class Codex object: its members, its L1 to L4 delegation classifications, its escalation paths, its approval thresholds. When a merge request proposes a change to a specification or a principle, the Codex resolves the required reviewers from the Council’s organizational model rather than from a static CODEOWNERS file that ages out of sync with the actual governance structure.
When a compliance report is generated for an AI agent, the Codex names the accountable owner directly from the capability’s owningCouncilMember field.
The organizational model is the layer that connects architectural artifacts to named human accountability, which is the form that governance eventually takes in any regulated environment.
3.5. The enterprise’s cognitive infrastructure
Together, business capabilities, enterprise intent, semantic ontology, and organizational model form what the broader Codex literature calls the enterprise’s cognitive infrastructure.
The TOGAF building blocks from section 2 sit on top of this substrate, referencing it, binding to it, and deriving their applicability from it. A Codex that contains principles, but no capability map is a floating rulebook. A Codex that contains both is an enterprise decision system.
4. Why documents cannot carry these primitives
The case against document-centered architecture has been made many times, but the operational form of the argument is more specific than the cultural complaint. Documents fail as carriers of the four building blocks for structural reasons.
A principle written as prose is not a principle in any governable sense. It is a statement of preference, and to become operational it needs three additions that prose alone cannot carry: an applicability rule that says when it binds, a validation criterion that says how compliance is checked, and a metamodel mapping that anchors the principle to data the enterprise actually has. Without these additions, the principle cannot influence delivery except through human persuasion, and persuasion is not a control. An architect can cite the principle during review; a team can ignore it under deadline pressure; neither party can settle the disagreement without escalating to a governance forum, by which point the implementation choice has usually hardened. The principle remains rhetorical rather than operational.
A standards catalog written as a list of approved technologies is similarly thin. It tells a reader what is on the list, but it does not tell the reader whether the team’s proposed component is on the list, how to find out, what to do if the component is missing, what deprecation timeline applies to items being phased out, or how exceptions are recorded. Without conformance checks bound to the catalog and applicability scopes attached to each entry, the standard exists as reference material but enforces nothing.
A reference architecture written as a static diagram suffers the worst form of decay. The diagram captures a snapshot of how a particular type of system was designed at a particular time, with a particular set of policies in force. When any of those underlying conditions changes (a new principle is added, a vendor is deprecated, a compliance framework updates, a platform replaces another), the diagram does not change with them. It must be manually re-drawn, which means in practice that it is not re-drawn. Teams reach for it, find it stale, and quietly stop reaching for it.
A blueprint written as a target-state slide deck is the most vulnerable of the four. It often represents the most political work product the architecture team produces, with the longest production cycle and the shortest useful life. By the time a blueprint reaches steering-committee approval, the conditions that motivated it have usually shifted. A blueprint that cannot be regenerated cheaply when conditions change is a one-shot artifact, not a planning tool.
What unites these failure modes is that documents preserve content but not the logic between content. A principle is stored without its validation, a standard without its conformance check, a reference without the projection rules that would let it regenerate, and a blueprint without the dependency graph that would let it be sequenced.
5. The Codex as typed, linked, executable knowledge
The Enterprise Architecture Codex is the alternative this book has been developing. It is a way of organizing architectural knowledge so that the four building blocks become typed objects rather than documents. The objects carry relations between them, lifecycle states, and validation logic that executes. They include metamodel mappings that bind them to the data sources the enterprise already has.
5.1. The need for Typed Objects
A typed object means that every architectural artifact has a schema:
- A principle has fields for its statement, rationale, implications, validation criteria, exceptions, and related principles.
- A standard has fields for its scope, applicability, conformance check, and deprecation timeline.
- A reference architecture has fields for its layers, components, relations, and the underlying policies it expresses.
- A blueprint has fields for its target state, transitions, dependencies, and KPIs. The schema is the format in which the object is written, reviewed, and maintained, and two architects writing the same kind of artifact produce structurally comparable outputs because the schema constrains them to.
5.2. Typed Objects Have Relations
Explicit relations mean that an object names the other objects it depends on:
- A principle names the standards that operationalize it
- a standard names the components it applies to
- a reference architecture names the principles it satisfies and the standards it composes,
- a blueprint names the reference architectures it deploys.
The relations form a graph that can be traversed automatically, so that when a principle changes, the graph identifies every standard, reference, and blueprint that depends on it.
5.3. Typed Objects Own a Lifecycle
Lifecycle states mean that an object knows whether it is in draft, approved, deprecated, or superseded status. A standard whose lifecycle has moved to deprecated is still in the Codex but produces a different conformance result. A reference architecture whose lifecycle is draft cannot be cited as authoritative in delivery.
5.4. Validation Logic is Then Possible
Validation logic that executes means that the Codex content carries the checks needed to evaluate compliance, not only the description of what compliance would require:
- A principle’s validation criteria are written in a form that a tool can run against the data.
- A standard’s conformance check produces a pass-or-fail result for a specific application.
The Codex is read by humans for understanding and read by tools for evaluation, from the same source.
5.5. The Role of the Metamodel
Metamodel mappings mean that abstract Codex concepts are anchored to concrete data the enterprise already collects.
A principle about cloud-first deployment maps to a specific field on the application fact sheet in the enterprise’s portfolio system. A standard for integration patterns maps to interface relations in that same system. The Codex is not a parallel universe of architectural concepts.
It is the semantic layer that makes the data the enterprise already has into architectural meaning.
Examples were numerous to prove that this pattern works at scale:
- the GOV.UK Service Standard demonstrates that governance improves when expectations and assessment criteria are made explicit and shared.
- Backstage shows that a typed software catalog with structured ownership outperforms wiki-based service documentation.
- Crossplane shows that infrastructure can be expressed as declarative resource compositions that compose, validate, and deploy.
6. Packaging the Codex as skills, distributed through Claude marketplaces
The conceptual structure described above needs a physical form. The form that has recently emerged packages the Codex as a set of composable skills, stored in a Git repository, and distributed through marketplace-style endpoints into the AI clients that consume them.
This section shows the concrete artifacts: the repository layout, the skill file format, and the client configuration.
6.1. Git repository layout
An enterprise Codex lives in a single Git repository with a predictable folder structure. The layout in Figure 2 below is an example of what could be the shape of the ACME Pharma Codex, with one folder per skill and one YAML file per typed object. The `.claude/` directory at the root carries the configuration that Claude Desktop and Claude Code read when the repository is published as a marketplace endpoint. You can adapt it based on your AI tooling.
acme-codex/
├── README.md
├── .claude/
│ ├── marketplace.json # marketplace manifest for client discovery
│ └── settings.json # skill routing and activation rules
├── skills/
│ ├── ea-principles/
│ │ ├── SKILL.md # skill frontmatter + routing description
│ │ ├── general/
│ │ │ ├── APP-001-cloud-first.yaml
│ │ │ ├── SEC-002-least-privilege.yaml
│ │ │ └── DATA-003-personal-data-minimization.yaml
│ │ └── ai/
│ │ ├── AI-001-agent-registration.yaml
│ │ ├── AI-004-risk-classification.yaml
│ │ ├── AI-005-human-in-the-loop.yaml
│ │ ├── AI-006-constrained-autonomy.yaml
│ │ └── AI-015-eu-ai-act-readiness.yaml
│ ├── ea-standards/
│ │ ├── SKILL.md
│ │ └── catalog/
│ │ └── STD-AI-004-policy-engine.yaml
│ ├── ea-reference-architectures/
│ │ ├── SKILL.md
│ │ └── REF-AIAGENT-001-ai-agent.yaml
│ ├── ea-blueprints/
│ │ ├── SKILL.md
│ │ └── ROADMAP-AIAGENT-PV-001.yaml
│ ├── business-capabilities/
│ │ ├── SKILL.md
│ │ └── pharmacovigilance/
│ │ ├── CAP-PV-000-pharmacovigilance.yaml
│ │ ├── CAP-PV-001-adverse-event-intake.yaml
│ │ └── CAP-PV-002-safety-case-normalization.yaml
│ ├── enterprise-intent/
│ │ ├── SKILL.md
│ │ └── INTENT-PV-001.yaml
│ ├── enterprise-ontology/
│ │ ├── SKILL.md
│ │ └── glossary/
│ │ ├── adverse-event.yaml
│ │ └── customer.yaml
│ ├── ea-council/
│ │ ├── SKILL.md
│ │ ├── council-charter.yaml
│ │ └── delegation-classes.yaml # L1 to L4 definitions
│ ├── bmad/
│ │ └── SKILL.md # Brief / Map / Act / Double-check
│ ├── compliance/
│ │ ├── SKILL.md
│ │ └── scoring-weights.yaml
│ └── diagram-generation/
│ ├── SKILL.md
│ └── templates/
├── references/
│ ├── togaf-content-framework.md
│ └── regulatory-anchors.md
└── tests/
└── scenarios/
└── pharmacovigilance-scenario-pack.yamlFigure 2: Git repository layout for the ACME Pharma Codex.
The layout distinguishes three concerns:
- Top-level skill folders hold the typed objects grouped by kind: principles, standards, references, blueprints, capabilities, intent, ontology, council, operating model, compliance, rendering.
- Each skill folder carries a SKILL.md that defines how the skill is activated and a set of YAML files that carry the typed objects themselves.
- Cross-cutting material (references, tests) lives at the root outside the skills tree.
6.2. Skill file format
Every skill folder contains a SKILL.md with YAML frontmatter and a markdown body:
- The frontmatter is what Claude Desktop and Claude Code use to decide when to load the skill into the current conversation.
- The body is the substantive content that gets loaded when the skill activates.
The fragment below is the opening of the ea-principles skill.
- The name and description fields carry the routing information.
- Claude’s skill-aware client reads the description and triggers when the user’s request matches one of the contexts or keywords.
- The dependencies field declares that this skill composes with others (the ontology skill to resolve terms, the council skill to identify required reviewers, the capabilities skill to establish scope).
- The markdown body is loaded only when the skill activates, so the context window is not consumed by every skill in the Codex on every interaction. Figure 3 below shows a concrete skill file.
# FILE: skills/ea-principles/SKILL.md
---
name: ea-principles
description: |
ACME Pharma enterprise architecture principles. Activates when
reviewing an application design, assessing an AI agent, authoring
a new design decision, or evaluating compliance. Provides the
principle catalog (6 general, 14 AI-specific), applicability
rules, and validation logic bound to LeanIX fact sheet data.
version: 2.3.1
triggers:
keywords:
- principle
- AI principle
- compliance check
- EU AI Act
- design review
contexts:
- design-review
- agent-assessment
- decision-authoring
- merge-request-review
dependencies:
- enterprise-ontology
- ea-council
- business-capabilities
---
# ACME Pharma Architecture Principles
This skill provides the 20 architecture principles governing
application and AI-agent design at ACME Pharma. Principles are
organized into two groups: 6 general principles (applications,
security, data, integration) and 14 AI-specific principles
(AI governance, AI architecture, AI operations).
## How to use this skill
When asked to evaluate an application or AI agent, load the
relevant principles based on the entity's category:
...Figure 3: Skill file format: ea-principles/SKILL.md.
6.3. Marketplace configuration for Claude clients
The .claude/marketplace.json manifest at the repository root declares the Codex as a marketplace endpoint that Claude Desktop and Claude Code can subscribe to (Figure 4 below). The manifest names the skills the endpoint publishes, declares their version, and tells the client how to refresh them. A minimal manifest looks like this:
// FILE: .claude/marketplace.json
{
"name": "acme-ea-codex",
"version": "2026.04",
"description": "ACME Pharma Enterprise Architecture Codex",
"source": {
"type": "git",
"url": "https://github.com/acme-pharma/ea-codex.git",
"branch": "main",
"skillsPath": "skills/"
},
"publishedSkills": [
"ea-principles",
"ea-standards",
"ea-reference-architectures",
"ea-blueprints",
"business-capabilities",
"enterprise-intent",
"enterprise-ontology",
"ea-council",
"bmad",
"compliance",
"diagram-generation"
],
"refresh": "on-session-start",
"accessControl": {
"requiredGroups": ["ea-practitioners", "platform-engineering"]
}
}Figure 4: Marketplace manifest: .claude/marketplace.json.
On the client side, an architect using Claude Code adds the marketplace endpoint to the project or user configuration. The relevant entry in a Claude Code configuration file looks like Figure 5 below:
// FILE: ~/.claude/config.json (or .claude/config.json in a project)
{
"marketplaces": [
{
"name": "acme-ea-codex",
"endpoint": "https://github.com/acme-pharma/ea-codex.git",
"branch": "main",
"autoUpdate": true
}
]
}Figure 5: Claude Code client configuration: ~/.claude/config.json.
Once configured, Claude Code pulls the Codex skills on session start and loads them into context on demand based on the triggers in each skill’s frontmatter.
An architect asking, “is the AI Triage Service compliant with our AI principles?” causes Claude Code to load the ea-principles skill, the compliance skill, the business-capabilities skill (to resolve CAP-PV-001), and the ea-council skill (to identify the accountable owner) into context automatically.
The architect does not have to remember which skill applies; the skill frontmatter declares the match conditions and the client routes accordingly. The same mechanism works in Claude Desktop with the same manifest format, so the EA team’s content reaches architects at their editor and reviewers at their desktop from the same Git source of truth.
6.4. Three distribution layers in one manifest
An enterprise’s Codex is composed from three layers:
- Internal skills are proprietary to the enterprise and capture its specific principles, standards, references, capabilities, and operating procedures.
- Shared skills cross teams within the enterprise and provide common capabilities such as portfolio inventory, compliance scoring, and capability mapping.
- Public skills come from the wider community of practice and provide general-purpose capabilities such as TIME analysis, cloud migration planning, or transformation road mapping that the enterprise does not need to write itself.
The manifest above can declare all three layers by referencing multiple source repositories:
- the enterprise’s private Codex repo for internal skills,
- a shared-services repo for cross-team capabilities,
- a public marketplace endpoint for community skills.
Clients merge the three layers at load time, with enterprise-local skills taking precedence when triggers overlap. The marketplace pattern handles the composition naturally because each layer is a Git source of truth independently governed but consumed through the same mechanism.
The concrete configuration above is how the Codex stops being a concept and becomes a working artifact in an architect’s daily tooling.
The exact schemas and client configuration mechanisms continue to evolve as Anthropic and the broader ecosystem stabilize the plugin and marketplace story, but the pattern is clear: Git repository holds the Codex, marketplace manifest exposes it, Claude clients subscribe to it, skills activate on trigger match, and architectural content reaches the point of use without anyone having to paste it into a prompt.
7. Automating the four building blocks
Each of the four building blocks now has a worked form in the Codex. This section describes how each is encoded as a skill and how the encoding turns the artifact from a document into an automation. The examples below are drawn from a Codex example invented to describe ACME Pharma’s enterprise architecture practice.
7.1. Architecture Principles in the Codex
The architecture principle is the building block where the Codex contribution is most visible. A dedicated principles skill carries 20 principles, organized as 6 general principles covering applications, security, data, and integration, and 14 AI-specific principles covering AI governance, AI architecture, and AI operations.
Each principle has a schema with fields for the statement, the rationale, the implications, a validation criteria table, the link to the enterprise architecture tool metamodel mapping, exceptions, and related principles.
The validation criteria table specifies for each criterion the check method (EA tool field, survey question, or manual check) and the required value.
This format means that a principle is not a paragraph asking teams to do the right thing. It is a structured object whose validation logic can be executed (see Figure 6 below) by a companion compliance skill against the EA tool data in the enterprise’s portfolio system. The compliance result is scored, weighted (high-risk AI agents receive double weight on critical principles such as risk classification, human-in-the-loop, constrained autonomy, and EU AI Act readiness), and reported with a per-principle breakdown of what passed, what failed, and why. The principle becomes operational on first use rather than after a multi-month adoption campaign.
apiVersion: ea.codex/v1
kind: ArchitecturePrinciple
metadata:
id: AI-005
name: Human-in-the-Loop Escalation
category: AI Governance
status: approved
spec:
statement: >
AI agents operating within the enterprise must have an explicit
human review route for any output that modifies a system of
record, authorizes a regulated action, or closes a regulated task.
rationale: >
Unsupervised agent execution in regulated contexts creates
unreviewable risk. A human review route preserves accountability
even as agent execution scales.
appliesTo:
factSheetTypes:
- Application
filter:
category: aiAgent
validation:
check: LeanIXFieldCheck
field: humanReviewRoute
expected: non-empty
severity: high
relatedPrinciples:
- AI-001
- AI-006
- AI-015Figure 6: ArchitecturePrinciple typed object for Human-in-the-Loop oversight (AI-005).
The file is readable by a human reviewer and loadable by the compliance engine:
- The statement and rationale carry the architectural content,
- the appliesTo field names the fact-sheet type and filter that the principle binds to, and the validation field names the executable check that runs against every fact sheet in scope.
The same artifact is consumed by the architect proposing changes, the merge-request reviewer approving them, the compliance engine scoring the portfolio, and the AI assistant answering questions about what the enterprise expects of its AI agents. The typed, linked, executable form is concrete rather than aspirational.
7.2. Architecture Standards in the Codex
Architecture standards follow the same pattern but anchor differently. A standard is a constraint on technology usage, applied where the enterprise has decided that consistency matters more than local choice.
The difficulty with traditional standards is that the catalog ages faster than the catalogers. A standards document declares that a database technology is approved in 2023, restricted in 2024, deprecated in 2025, and then nobody revises the document in 2026 because no one owns the revision cycle.
The Codex treatment makes the standard a typed object whose radar position is derived from evidence rather than assigned by committee, whose validation runs against actual portfolio technology usage, and whose exception process is part of the object itself rather than a separate workflow document.
Figure 7 below is STD-AI-004, the policy-engine standard that underpins the Rego policy shown later in section 9. The reader should notice the explicit linkage to the principles the standard enforces, the machine-checkable validation against LeanIX IT-component data, and the obsolescence signals that can cause the standard to be reopened before anyone schedules a review.
apiVersion: ea.codex/v1
kind: TechnologyStandard
metadata:
id: STD-AI-004
name: Policy-as-Code Engine for AI Agent Gateways
category: AI Architecture
status: approved
radarPosition: adopt
lastReviewed: "2026-01-20"
spec:
principleRef: AI-005
scope: AI agent gateway policy enforcement in regulated domains
patterns:
- id: PAT-OPA-001
name: Open Policy Agent (Rego)
classification: preferred
use: >
Sole permitted policy-as-code engine for AI agent gateways
operating on high or limited risk classifications.
applicableWhen: >
Application.category=aiAgent AND
riskClassification in [high, limited]
technology:
name: Open Policy Agent
minimumVersion: "0.65.0"
languageRequired: Rego
vendorSupport: open-source-LTS
applicability:
factSheetTypes:
- Application
filter:
category: aiAgent
riskClassification: [high, limited]
constraints:
- deploymentMode: sidecar OR gateway-embedded
- policyBundleSource: Codex-generated only
- evaluationLatencyP99Ms: 50
- auditLog: every decision recorded with policy hash and input hash
exceptionProcess:
owner: ai-governance-board
slaBusinessDays: 5
requiresCompensatingControl: true
validation:
check: LeanIXTechnologyStackCheck
against: ITComponent.technology
rule: >
For every Application with category=aiAgent and riskClassification
in [high, limited], a related ITComponent must resolve to
Open Policy Agent v0.65.0 or later.
severity: high
obsolescenceSignals:
- signal: policyEvaluationLatencyDegradation
threshold: P99 > 100ms sustained 7 days
action: raise standard review
- signal: vendorEOL
action: begin migration planning within 90 days
linkedPrinciples:
- AI-005
- AI-006Figure 7: TechnologyStandard typed object for Policy-as-Code enforcement (STD-AI-004).
The standard does three jobs at once:
- It states what is approved through the technology, minimumVersion, and constraints fields.
- It states how the approval is verified through the validation rule that runs against the portfolio’s actual IT-component data.
- It states when the approval expires through obsolescenceSignals that can raise the standard for review without waiting for a scheduled cadence.
Other points to be noted:
- The radarPosition is a derived attribute rather than an assigned one, because the standard’s continued adopt status depends on the obsolescence signals returning green.
- The linkedPrinciples field anchors the standard to the AI-005 and AI-006 principles it operationalizes, so a change to either principle surfaces the standard for review automatically.
7.3. Reference architectures in the Codex
Reference architectures are the building block where the regeneration argument matters most, because the reference architecture is the form in which the enterprise expresses what a class of system should look like. A traditional reference architecture is a slide deck that ages quickly and is consulted inconsistently.
The Codex treatment turns the reference into a typed object whose components, layers, relationships, and invariants are declared rather than drawn, and whose diagram is generated from the declaration rather than separately maintained. Figure 8 below is REF-AIAGENT-001, the reference architecture for AI agents that the AI Triage Service is an instance of. The reader should notice that the relationships between layers carry policy bindings, that invariants are first-class and machine-checkable, and that the diagram itself is a rendered view of this content rather than an authored file.
apiVersion: ea.codex/v1
kind: ReferenceArchitecture
metadata:
id: REF-AIAGENT-001
name: acme-enterprise-ai-agent
title: Enterprise AI Agent Reference Architecture
category: AI Architecture
status: approved
version: "2.1"
spec:
appliesTo:
factSheetTypes:
- Application
filter:
category: aiAgent
layers:
- id: governance
position: 1
role: Policy enforcement, principle validation, audit capture
requiredComponents:
- PolicyEngine
- AuditStore
- PrincipleValidator
- id: orchestration
position: 2
role: Intent routing, tool arbitration, human escalation
requiredComponents:
- AgentGateway
- HumanReviewQueue
- ToolCatalog
- id: agent
position: 3
role: Reasoning, retrieval, response formulation
requiredComponents:
- ReasoningModel
- RetrievalAdapter
- PromptContextBuilder
- id: data
position: 4
role: Authoritative state, grounded sources, evidence capture
requiredComponents:
- SystemOfRecord
- KnowledgeBase
- EvidenceStore
relationships:
- from: agent.ReasoningModel
to: data.KnowledgeBase
via: agent.RetrievalAdapter
type: readOnly
policyBinding: AI-006/prohibitedActions
- from: agent.ReasoningModel
to: data.SystemOfRecord
via: orchestration.AgentGateway
type: gatedWrite
policyBinding: AI-005/humanReviewRoute
- from: orchestration.AgentGateway
to: governance.PolicyEngine
type: preActionCheck
blockingOnDeny: true
invariants:
- id: INV-001
rule: >
No relationship of type directWrite from agent
to data.SystemOfRecord may exist.
severity: critical
- id: INV-002
rule: >
Every agent action produces an AuditStore entry
within 500 ms of the action completing.
severity: high
renderedBy:
skill: ai-agent-architecture-diagram
inputSource: LeanIX fact sheet of the agent and its related components
output: PNG plus machine-readable layer graph
derivedFromPrinciples:
- AI-001
- AI-005
- AI-006
- AI-015Figure 8: ReferenceArchitecture typed object for the Enterprise AI Agent pattern (REF-AIAGENT-001).
The reference architecture is a declaration of what an AI agent must be rather than a picture of what one can look like.
- The four layers of the reference architecture for AI Agent are ordered rather than suggestive, and each layer’s requiredComponents list names the concrete constituents that any instance must exhibit.
- The relationships section turns the arrows between boxes into typed claims: a ReasoningModel may read from a KnowledgeBase only via a RetrievalAdapter, and any attempt to write to the SystemOfRecord must route through the AgentGateway.
- The policyBinding fields link each relationship to the principle whose validation rule governs it.
- The invariants section is where the reference becomes executable: INV-001 can be checked against the agent’s actual relationship graph in the EA tool (for example LeanIX), and INV-002 can be checked against the agent’s audit-store integration.
A reference architecture that passes both invariants is consistent with the reference; one that fails either is not. The diagram that appears in review decks is rendered by the ai-agent-architecture-diagram skill from this content, which means the diagram and the declaration cannot drift apart.
7.4. Blueprint in the Codex
The Codex treatment makes the blueprint a typed sequence of transitions between Codex-resident building blocks, with each transition carrying its preconditions, deliverables, KPIs, and exit gate.
The difficulty with traditional blueprints is that they describe a destination without a traversable path: a slide shows the target state, but no artifact shows what must be true at each milestone for the target to remain reachable.
Figure 9 below is ROADMAP-AIAGENT-PV-001, the rollout plan for the AI Triage Service across three regions. The reader should notice that preconditions reference the principle compliance results and the Rego policy coverage directly, that each transition defines KPIs with explicit targets, and that feedback signals can trigger revision of the underlying specification without waiting for the next strategic review cycle.
# Local non-canonical extension — not part of EA Codex v1.1.0.
# TransformationRoadmap is not a typed kind in canonical v1.1.0; ACME Pharma uses it
# as a local Codex extension while a blueprint kind is considered for v2.
apiVersion: ea.codex.local/v1alpha1
kind: TransformationRoadmap
metadata:
id: ROADMAP-AIAGENT-PV-001
name: AI Triage Service Rollout for Pharmacovigilance
status: approved-for-execution
targetCapability: adverse-event-intake
horizonMonths: 24
spec:
currentState:
applications:
- { id: pharmacovigilancePlatform, time: Invest }
- { id: regionalWorkflowEU, time: Tolerate }
- { id: regionalWorkflowNA, time: Tolerate }
- { id: regionalWorkflowAPAC, time: Eliminate }
targetState:
applications:
- pharmacovigilancePlatform # retained as system of record
- aiTriageService # new, bound to REF-AIAGENT-001
- workflow-v2 # consolidates regional workflows
transitions:
- id: T1-controlled-pilot
timelineMonths: "0-6"
region: EU
preconditions:
- principleCompliance:
principles: [AI-001, AI-004, AI-005, AI-006]
result: PASS
- regoPolicyCoverage: 100%
- regionalVariant: EMA-aligned-v1 approved
deliverables:
- deploy aiTriageService in EU staging
- integrate with pharmacovigilancePlatform via gatedWrite
- baseline intake latency and override rate
kpis:
- intakeLatencyP50Hours: target 8, baseline 48
- aiOverrideRatePercent: target 35
- blockedActionCount: target trending down
exitGate: council review signed off on baseline
- id: T2-staged-extension
timelineMonths: "6-15"
regions: [NA, APAC]
dependsOn: [T1-controlled-pilot]
preconditions:
- T1 exitGate PASS
- regional variation envelope validated per region
deliverables:
- roll out to NA with FDA-aligned audit adapter
- roll out to APAC with PMDA-aligned audit adapter
- retire regionalWorkflowAPAC, migrate queues to workflow-v2
kpis:
- regionalExceptionCount: 5 per region per quarter
- evidenceCompletenessRatePercent: 98
- id: T3-scale-operations
timelineMonths: "15-24"
dependsOn: [T2-staged-extension]
deliverables:
- consolidate regional workflows onto workflow-v2
- retire regionalWorkflowEU and regionalWorkflowNA
- extend aiTriageService to partner-reported intake channel
kpis:
- portfolioApplicationCountReduction: 2
- intakeLatencyP50Hours: target 4
feedbackSignals:
- source: PolicyEngine blocked-action log
action: inform T2 and T3 decision refinement
- source: override-rate anomaly detection
trigger: rate > 50% sustained 2 weeks
action: revise AP-PV-001
linkedArchitecturePackages:
- AP-PV-001
linkedPrinciples:
- AI-001
- AI-004
- AI-005
- AI-006
- AI-015Figure 9: TransformationRoadmap (local non-canonical extension; not part of EA Codex v1.1.0) for the AI agent rollout (ROADMAP-AIAGENT-PV-001).
The blueprint is a traversable path rather than a target picture.
Each transition names preconditions that must be true before it can begin, deliverables that it must produce, KPIs that measure whether its effects match the intent, and an exit gate that must clear before the next transition starts. The preconditions are not narrative promises but checkable predicates that reference Codex content directly: T1 cannot begin until principleCompliance for AI-001, AI-004, AI-005, and AI-006 returns PASS against the EA tool (here LeanIX fact sheet), until the Rego policy covers all required rules, and until the regional variant is approved.
The KPIs return structured signals: the AI override rate at 35 percent is a target, and the feedbackSignals section declares that sustained rates above 50 percent automatically trigger revision of AP-PV-001.
The roadmap and the specification form a feedback loop, not a one-way plan.
The reader who has followed the earlier fragments will notice that the roadmap references:
- STD-AI-004 implicitly through regoPolicyCoverage
- REF-AIAGENT-001 through the aiTriageService binding
- AP-PV-001 explicitly through linkedArchitecturePackages,
- Five principles through linkedPrinciples.
7.5. Synthesis
It must be noted that:
- All four TOGAF building blocks appear together in a single execution plan because they are all typed objects in the same Codex
- The pattern across the four building blocks is consistent.
The Codex content carries two layers:
- A conceptual layer that states what the principle says, what the standard requires, what the reference architecture looks like, and what the blueprint targets.
- An operational layer that states how the principle is validated, how the standard is checked, how the reference is rendered, and how the blueprint is sequenced.
The artifact and its automation are facets of the same Codex object.
8. Producing TOGAF deliverable forms
Catalogs, matrices, and diagrams are the three deliverable forms that EA practice has used for decades to communicate its work. The Codex does not retire these forms; it changes how they are produced. Each form becomes a generated view over Codex content, refreshable on demand from the same source data the principles, standards, references, and blueprints already use.
8.1. Catalogs
Catalogs are the simplest form to generate. An application-inventory skill for example produces a list of applications matching specified criteria such as hosting type, criticality, lifecycle, owner, technical fit, or functional fit.
For ACME Pharma’s pharmacovigilance landscape, the list includes the AI Triage Service that a later chapter examines in depth, the regional workflow tools, the customer interaction platform, and the pharmacovigilance platform itself. Each entry carries its current lifecycle phase, its responsible owner, its risk classification, and its compliance status against the applicable principles.
The list can be generated from the EA tool through a search skill, with a semantic ontology skill providing the interpretation layer that turns raw fields into architectural meaning.
The catalog regenerates when the underlying data changes, which means it shows the current state of the portfolio rather than the state at the last manual update.
8.2. Matrices
The classic example is the business-capability against application-coverage matrix, generated by a capability-mapping skill.
For ACME Pharma’s pharmacovigilance domain, the matrix is built along two axes: the capability axis lists Adverse Event Intake, Safety Case Normalization, Human Medical Review, and Regulatory Submission Preparation, and the application axis lists the supporting systems.
The cells show which applications support which capabilities, where coverage gaps exist, and where multiple applications create redundancy. The matrix is not a spreadsheet maintained in parallel with the application inventory but a derivation from the same Codex content, regenerated on demand. The same matrix can be sliced by region, by criticality, or by AI risk classification by changing the generation parameters.
8.3. Diagrams
Diagrams are where the Codex contribution is most visible because diagrams are the most labor-intensive deliverable to maintain manually. The AI agent architecture diagram skill, already discussed in the reference-architecture context, produces the four-layer diagram for any AI agent registered in the EA tool.
All diagrams (capability heat maps, technology radars, integration dependency views, transformation roadmap timelines) are produced by a skill using the same projection-over-content pattern.
A diagram-review-checklist skill provides quality gates for any diagram produced through the Codex, ensuring that conventions for legend, layout, color coding, and labeling are applied consistently.
The economic effect of this approach is significant. The traditional EA function spends a substantial fraction of its time keeping deliverables current: diagrams are re-drawn when the landscape changes, matrix queries are re-run by hand when a stakeholder asks for an updated view, and the application catalog is refreshed every quarter for the operational review. When deliverables are generated views, this work shifts from artifact maintenance to Codex maintenance. The architect who would have spent two days updating a capability matrix instead spends two hours updating the underlying Codex content and regenerates the matrix in a minute. The deliverables that the EA practice produces become more numerous, more current, and more diverse precisely because they are no longer manually authored.
9. ACME Pharma: the Codex and the EA Council producing governed deliverables
The ACME Pharma pharmacovigilance scenario provides a concrete case to walk end to end through the Codex. It also makes visible the relationship between the Codex as a body of knowledge and the governance structure that owns it.
Chapter 4 introduced ACME Pharma’s EA Council as the four-layer design authority that governs the enterprise’s AI footprint, with delegation classifications L1 through L4 distinguishing actions an agent may take autonomously (L1) from actions requiring named human accountability (L4).
The Codex is the artifact through which the Council exercises that authority. Without the Codex, the Council’s decisions live in meeting minutes and slide decks. With the Codex, they live as typed objects that delivery systems read directly.
9.1. AI-assisted adverse-event intake architecture package
Imagine an ArchitecturePackage named AP-PV-001 for AI-assisted adverse-event intake. For purposes of this section, it defines the demand, the architectural concerns, the system model, and the agent permission boundary. It also references the design decision DEC-PV-001, which makes the pharmacovigilance platform the authoritative system of record.
The decision drives a set of derived rules, a variation envelope for regional adaptation, and an executable Rego policy that enforces the agent permission boundary.
The ArchitecturePackage lives in the Git repository under the appropriate skill or reference directory, is reviewed through merge requests, and is addressable by stable identifier from any other Codex object that needs to reference it.
The EA Council’s role here is concrete: AP-PV-001, the ArchitecturePackage, is the form in which the Council records its design authority over this capability, and any change to it follows the merge-request review process the Council has established.
The principles that govern the AI Triage Service are evaluated against this architecture package through the principle’s compliance skill.
- AI-001 (AI Agent Registration) checks that the agent has the required category, description, ownership subscription, and business-capability mapping in the EA tool (here LeanIX).
- AI-004 (Risk Classification) checks that the agent has a documented risk level and, if classified as high-risk, an approval state.
- AI-005 (Human-in-the-Loop Escalation) checks that the agent has an explicit human review route configured, which the Rego policy in the specification already enforces.
- AI-006 (Constrained Autonomy Zones) checks that the agent has explicit prompt content and an AI type field documenting its autonomy boundary, which the specification’s prohibitedActions list directly supports.
The compliance result is scored, weighted (high-risk agents receive double weight on AI-004, AI-005, AI-006, and AI-015), and reported with a per-principle breakdown. The Council reviews the score for every high-risk agent before approval and again on a regular cadence after deployment.
9.2. The executable form of these principles is a Rego policy
The executable form of these principles is a Rego policy that the enterprise’s policy engine evaluates whenever the agent attempts an action.
What “the Codex feeds the policy engine” means in concrete terms? Figure 10 below illustrates it with a concrete example: An executable Rego policy is generated from AI-005 and AI-006 bound to the AI Triage Service EA tool object. The reader should notice that no sentence from the principles document appears in this policy. The policy is derived from the validation fields of the principle objects and the prohibitedActions list in the agent’s fact sheet.
package acme.pharmacovigilance.ai_triage
# Generated from AI-005 and AI-006 applied to the AI Triage
# Service fact sheet in LeanIX. Enforced by the AI Gateway at
# every agent action.
default allow := false
# AI-005: Human review route must be configured.
deny[msg] {
input.agent.category == "aiAgent"
not input.agent.humanReviewRoute
msg := "AI-005 violation: humanReviewRoute is not configured"
}
# AI-006: Constrained autonomy. Prohibited actions must never fire.
deny[msg] {
prohibited := input.agent.prohibitedActions[_]
input.action == prohibited
msg := sprintf(
"AI-006 violation: action %v is outside the autonomy boundary",
[input.action])
}
allow { count(deny) == 0 }Figure 10: Rego policy generated from AI-005 and AI-006 for the AI Triage Service.
The policy runs inside the AI Gateway whenever the AI Triage Service attempts an action. It reads the agent fact sheet from the Codex data feed and the proposed action from the runtime request, and if either deny rule fires, the action is blocked and a violation record is written into the Codex’s feedback layer.
The same principles that appeared as architectural prose are now runtime constraints enforced at execution time.
This connects directly to the Council’s L1 to L4 delegation classification:
- an L1 action (an agent’s read-only retrieval against the knowledge base) passes the policy without further review
- an L3 action (a write to the regional workflow queue) passes only when the action is on the agent’s allow list and the human review route is present
- an L4 action (any modification to a regulated case in the pharmacovigilance platform) is blocked at the gateway because it falls into the prohibited actions list.
The Council does not need to be in the loop for every agent action; the Codex carries the Council’s policy in a form the runtime can enforce.
9.3. Reference architecture for the AI Triage Service
The reference architecture for the AI Triage Service is generated through the agent architecture diagram skill:
- The skill queries the agent’s EA tool and retrieves all related entities, which include the pharmacovigilance platform as the system of record, the customer interaction platform as the intake channel, the regional workflow tools as work queues, and the document processing service as the extraction layer.
- It then renders the four-layer diagram with semantic placement, positioning governance components at the top, orchestration through the AI Gateway in the middle-upper layer, the AI Triage Service itself just below that, and the data layer at the bottom.
The diagram is then a current view over Codex content, not a separately authored file, so when the regional workflow integration changes, the next render reflects the change without anyone redrawing the picture.
9.4. Blueprint for the AI Triage Service
The blueprint for the rollout is generated through the transformation-roadmap skill. The roadmap shows three stages:
- a controlled pilot in Europe matching the controlled-pilot status named in the specification’s metadata
- a staged extension reaching North America and APAC (the regions named in the variation envelope)
- a target state with AI-assisted intake operating at scale across all regions while preserving the human review route.
Each transition carries dependencies, a timeline, and KPIs:
- The dependencies are concrete: the principle compliance checks must pass, the Rego policy must validate against the agent’s actual permission configuration, and the regional regulatory adaptation must be approved by the regional compliance authority named in the variation envelope.
- The KPIs come from the specification’s feedback section: intake latency, evidence completeness rate, AI triage override rate, blocked agent action count, and regional exception count.
The Council reviews these KPIs at each transition’s exit gate.
9.5. Deliverables for the AI Triage Service
The deliverable set for the Council’s review is generated as three projections over the same Codex content:
- The catalog is the AI agent inventory, listing the AI Triage Service alongside any other AI agents in the pharmacovigilance landscape with their current lifecycle, risk classification, and compliance status.
- The matrix is the capability coverage view, showing how the AI Triage Service supports adverse-event intake while the pharmacovigilance platform retains case-management authority.
- The diagram is the four-layer reference architecture rendered from REF-AIAGENT-001.
All three deliverables come from the same Codex content and none of them are maintained as separate files, which means the Council reviews the current state and asks for variations rather than approving finished documents. A variation might be a different slice, a deeper view of one capability, or a forward projection to the target state, and in each case, it is produced on demand rather than scheduled for the next quarterly architecture committee.
10. What this changes for architects
The architect’s day-to-day work shifts in a way that some practitioners welcome and others find disorienting. The shift is real either way and worth naming explicitly.
Artifact authoring becomes Codex stewardship. The architect who would have spent a week drafting a reference architecture document now spends a week refining the principles, the schema, and the projection rules from which the reference architecture is generated. The product of the work is the Codex content, and the deliverable artifacts are byproducts of that content. This is a different identity than producing diagrams and decision documents that bear the architect’s name. The work is more leveraged because it produces many deliverables from the same content, but it is also more abstract because the architect rarely sees the final form of the deliverable while writing.
Review work becomes merge-request review. The architect no longer redlines Word documents over email or sits in a review meeting walking a stakeholder through a slide deck. The architect reviews proposed changes to Codex content through the Git repository’s merge-request flow, with the same conventions of comment threads, approval requirements, and audit trails that engineering review has used for years. Architects who have not previously worked with Git workflows need to acquire the relevant fluency, but the pattern is well established, and the tooling support is mature.
The architect’s audience expands. A document is read by humans. A Codex skill is read by humans and loaded by AI assistants. A principle whose validation criteria are written in executable form is run by the compliance engine against every new application that enters the portfolio. The architect’s work reaches further than it did before, and it must also be more precisely written, because content that is loaded by an AI assistant or executed by a compliance check has less tolerance for ambiguity than a document a human will interpret in context.
The shift is from author of artifacts to product owner of a technical reference system. The work is no less substantive, but less individual and more compositional.
11. Costs, limits, and failure modes
The Codex pattern has known weaknesses, and an honest assessment helps any team adopting it to avoid the predictable mistakes.
The Codex-as-prompts risk is the most subtle. When Codex content is loaded by an AI assistant as part of its instruction context, the assistant’s interpretation of the content depends on the model’s prompt-following behavior. As models change, the same Codex content can be interpreted differently. A principle that the previous model version applied strictly may be applied loosely by the new version, or the reverse, without any change to the Codex itself. The mitigation is an evaluation harness that runs representative scenarios against the Codex on each model change and surfaces interpretation drift before it affects production work. Without that harness, the Codex’s stability is borrowed from the model and can be revoked silently.
The skill marketplace risk arises as the Codex grows. When the number of skills crosses a threshold, the routing layer becomes harder to maintain, skills with overlapping triggers compete for activation, and skills with unclear provenance accumulate without anyone owning their continued maintenance, so quality drifts. The mitigation is editorial discipline. The Codex needs an owner who reviews new skill proposals, retires skills that are no longer needed, and resolves overlap before it becomes confusion. Another option is to apply the divide and conquer algorithm and to package skills as “sub-agent” to delegate the tasks to.
The Git discipline dependency is real but solvable. If merge-request review on the Codex repository becomes sloppy, the content decays in exactly the way it would have decayed as Word documents. The Codex inherits the discipline of the Git workflow it sits in, no more and no less. Enterprises with mature engineering practice will find the Codex easy to govern, while enterprises whose Git practice is itself weak will find the Codex inheriting the same weakness.
The coverage gap problem is structural. What is not in the Codex is not governed, because a principle that has not been written cannot be checked and a standard that has not been catalogued cannot be enforced. The Codex provides force where it has content and provides nothing where it has gaps. This is a feature in some respects because it is honest about what is and is not under control, but it places a real burden on the team that owns the Codex to map and fill the gaps deliberately rather than discovering them the hard way.
Schema evolution discipline matters because changes to a schema affect every artifact that uses it. Changing the principle schema to add a new field affects every principle in the catalog. Migration plans, backward compatibility, and version pinning are necessary parts of Codex maintenance. The skill-creator workflow provides the conventions; the team must commit to following them.
Organizational change is the predictable obstacle. Architects accustomed to authoring documents in Word and diagrams in Visio do not always welcome the shift to schemas, YAML, Git, and merge requests. Some find it liberating; others find it alienating. Adoption is a change-management question, not a technology question.
12. What a Codex concretely looks like
This chapter has introduced the Codex through a sequence of pieces: the vibes-to-codex framing, the four TOGAF building blocks, the business-domain substrate, the typed-linked-executable form, the Git-plus-marketplace packaging, the worked ACME Pharma example. It is worth bringing the pieces together into the picture in Figure 11 below of what a mature Codex contains.
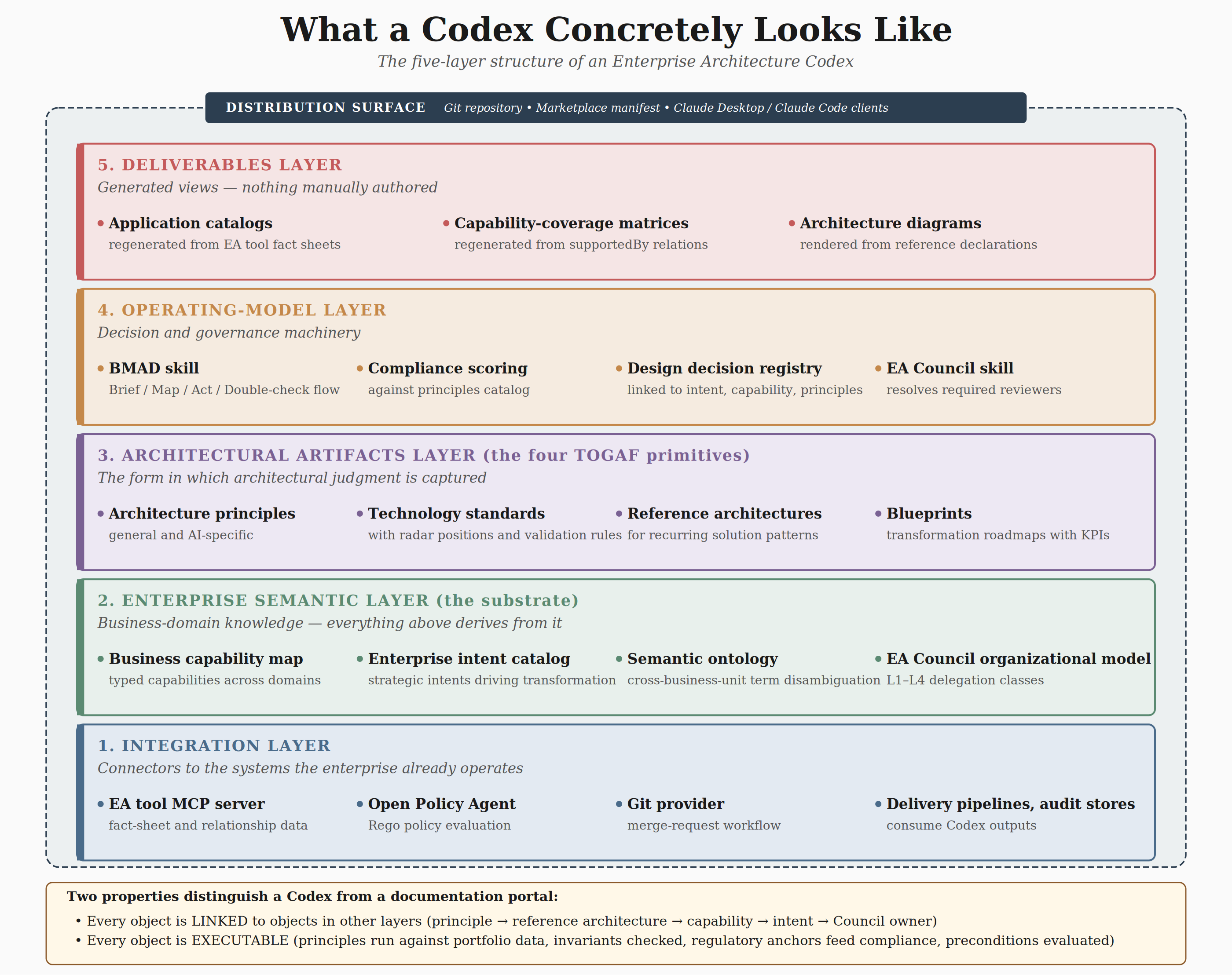
Figure 11: Five-layer structure of the Codex, each layer implemented as one or more skills in the Git repository.
Seen as a stacked structure, the Codex has five layers, each implemented as one or more skills in the Git repository.
- The Enterprise Semantic layer carries the business-domain knowledge described in section 3: the business capability map, the enterprise intent catalog, the semantic glossary and ontology, and the organizational model including the EA Council’s four-layer structure and its L1 to L4 delegation classes. This layer is the substrate, everything above it derives from it.
- The Architectural Artifacts layer carries the four TOGAF building blocks described in sections 2 and 7: architecture principles, a standards catalog with their radar positions and validation rules, reference architectures covering the enterprise’s recurring solution patterns, and an active blueprint portfolio of transformation roadmaps at various stages of execution. This layer is the form in which architectural judgment is captured.
- The Operating Model layer carries the decision and governance machinery: the BMAD skill encoding the Brief-Map-Act-Double-check flow that Chapter 8 will develop, the compliance skill that scores applications and agents against the principles catalog, a decision registry of approved design decisions each linked to the intent, capability, and principles they invoke, and the EA Council skill that resolves required reviewers from merge requests. This layer is how the Codex content becomes a decision system rather than a reference.
- The Deliverables Layer carries the generation rules for the three deliverable forms described in section 8: application catalogs regenerated from EA tool, capability-coverage matrices regenerated from the capability map and its supportedBy relations, and architecture diagrams regenerated from reference architecture declarations via the diagram-generation skill. Nothing in this layer is manually authored. Every artifact is a view over the three layers below.
- The Integration Layer carries the connectors that link the Codex to the data systems the enterprise already operates: the EA tool MCP server for content and relationship data, the Open Policy Agent engine for Rego policy evaluation, the Git provider for merge-request workflow, and the delivery pipelines and audit stores that consume Codex outputs. This layer is the substrate between the Codex as a body of knowledge and the enterprise systems that act on it.
And wrapping all five layers is the Distribution Surface: The Git repository that holds the Codex, the marketplace manifest that exposes it, and the Claude Desktop and Claude Code clients that subscribe to it.
Every architect, engineer, and reviewer in the EA practice consumes the Codex through this surface, pulling updates as the Codex evolves and loading skills on demand as their work requires them.
The Codex is the form in which the enterprise’s existing architectural knowledge becomes actionable, not a new body of knowledge to be invented.
Final notes:
- Every object in every layer is linked to objects in other layers: the principle AI-005 links to the reference architecture REF-AIAGENT-001 via its policyBinding, which links to the capability CAP-PV-001 via its appliesTo scope, which links to the intent INTENT-PV-001 via its linkedIntent field, which links to the EA Council domain lead via its owningCouncilMember field. A change to any of these objects is traceable to every object that depends on it.
- Every object in every layer is executable: the principle runs against the EA tool data, the reference architecture’s invariants are checked against actual agent configuration, the capability’s regulatory anchors feed the compliance engine’s weighting, and the blueprint’s preconditions are evaluated against the current state rather than assumed. The Codex is not documentation about the enterprise, but the enterprise expressed in a form that both humans and systems can act on.
13. The impacts on EA tools
How the Codex pattern lands inside the EA tool vendor landscape is a separate question from whether the pattern is right, and it deserves a more careful treatment than “the two layers compose.”
Several futures are plausible, and they are not equally likely or equally advanced. Three scenarios dominate the current trajectory, and it is worth being explicit about what each one looks like in practice, which vendors and technologies are closest to realizing it, and what evidence supports their relative maturity as of early 2026.
13.1. The EA tool remains the dominant carrier and absorbs Codex capabilities
In this scenario, the incumbent EA platforms (Ardoq, SAP LeanIX, and their equivalents) evolve their metamodel, query surface, and AI integration to host the Codex capabilities described in this chapter directly.
Architects continue to work primarily inside the EA tool, but the tool exposes its content to AI clients through standardized interfaces, carries typed principles and standards as first-class objects, and extends its governance workflow to cover AI-agent registration and compliance scoring.
This is the most advanced of the three scenarios in shipped capability. Both major vendors, Ardoq and SAP LeanIX, improved substantially their AI and agentic AI capabilities over the past twelve months.
The honest caveat is that their capabilities still focus primarily on inventory, visibility, and conversational access to existing data, rather than on the typed principle-standard-reference-blueprint skill model described in this chapter.
A principle in Ardoq or LeanIX today is typically a text field on a governance object, not a typed schema whose validation runs against the portfolio.
I do think that EA tool with graph-native architecture (like Ardoq has), might have a decisive advantage to move towards our proposes codex model, especially in their capability to support non structured data and knowledge graph (and associated semantic).
13.2. The Codex absorbs EA tool functions
In this scenario, the Codex as a Git-distributed skill library becomes the primary surface, and the EA tool is either reduced to a data source, replaced by a lighter-weight alternative built on a general-purpose data platform, or eliminated entirely in favor of an engineering-stack architecture.
Several technology paths enable this scenario, and they are at different stages of maturity: adopting a new generation of AI-native EA tool, creating the codex on top of a modern “data platform”, or extending open-source EA governance toolkits. The best solution may be a combination of all three paths.
13.2.1. Adopt a new generation of AI-native EA tool
The closest to a turn-key AI-native EA platform built around the Codex pattern i found so far is Peaqview, which describes itself as “AI-native enterprise architecture”. It offers native process mining, full ArchiMate and BPMN support, AI Partners via MCP with over one hundred tools, and a unified data model built from day one rather than retrofitted.
Peaqview markets itself explicitly against the incumbent model with the framing that “enterprise performance gaps hide between layers” and that an AI-native platform reasoning across application, technology, process, and contract layers is structurally better positioned than a platform designed for static documentation.
It is a challenger rather than a market leader at this stage, but Peaqview demonstrates that the Codex pattern can be packaged as a product rather than assembled by each enterprise.
13.2.2. Create the codex on top of a modern “data platform”
A second path I firmly believe in, is the scenario of a general-purpose data platform plus graph overlay. This solution will come sooner or later into play because:
- Companies are investing massively in their data and associated platform. Or, one of the main reasons of EA tool project failure is data quality. So, let’s take the data where they are
- AI foundational platform is also being deployed in enterprises. So why not use that capability for Enterprise Architecture reasoning?
- Finally, the EA Codex all about orchestration, impact analysis and code generation and execution, and its implementation at scale is deeply rooted in tools software engineers use. The data platform is one of the easiest solutions to be used (compared to an EA tool in SaaS mode)
- Sovereignty is the final argument that is gaining traction, at least in Europe.
It must be noted that Databricks and Snowflake have both evolved substantially beyond their original warehouse and lakehouse distinction: both now offer native vector search, AI agents, governed access controls, and the open table formats (Delta, Iceberg) that let enterprises build on one while interoperating with the other.
On top of these, knowledge-graph overlays such as Neo4j (with its Databricks bi-directional bridge and its Snowflake Graph Analytics integration), Ontotext GraphDB, and Ontopic bring the semantic layer that lakehouses lack.
The technical feasibility of building an EA capability directly on Databricks or Snowflake with a graph overlay is now real, and I’m certain that large enterprises with mature data platforms will evaluate this approach.
The question is whether the application layer (principle schemas, compliance skills, deliverable generation) can reach production-grade maturity on this foundation without each enterprise building it from scratch, or whether open-source projects fill that gap.
One possible shortcut to that path is the usage of ServiceNow. ServiceNow can facilitate codex implementation since it is generally used to govern the infrastructure landscape (assets that runs in production), offers an extensible metamodel, and provide a solid platform with AI and Agentic platform on top. Using ServiceNow to build a digital twin and adding the codex on top could be a workable path.
13.2.3. Build on open-source EA governance toolkits
A third path is the extension of open-source EA governance toolkits. ArcKit is the clearest example. It is a Git-distributed, AI-assisted architecture governance toolkit that ships with 68 slash commands, ten research agents, and more than seventy document templates, with support across Claude Code, Gemini CLI, GitHub Copilot, Codex CLI, and OpenCode CLI.
Its 16-phase governance workflow follows UK Government standards (GDS Service Standard, Technology Code of Practice, Secure by Design), and its demonstration repositories cover regulated scenarios from NHS appointment booking to HMRC tax assistants.
ArcKit is not a complete replacement for an EA platform (it does not maintain an application portfolio or capability map as live objects), but it proves the authoring-and-governance layer of the Codex can be distributed as an open-source toolkit that works across AI clients. A
A Peaqview-style AI-native platform, combined with an ArcKit-style open-source toolkit, combined with a data platform underneath, represents the most plausible path by which the Codex absorbs the EA tool’s functions.
13.2.4. Make or buy is still the key question to answer
The caveat for this scenario is the build-versus-buy honesty check. Each of the three paths requires an enterprise to assemble components that traditional EA platforms sell pre-integrated: data management, metamodel governance, subscription workflows, role-based access, audit trail, and the accumulated best-practice content of the vendor’s customer base. A small enterprise can reasonably assemble these on Git and Databricks. A global regulated enterprise probably will not, except if it wants to build a sound digital twin (and then go beyond just enterprise architecture). This scenario is real, but it is more real for challengers, greenfield divisions, and technology-forward enterprises than for established regulated landscapes.
13.3. The two continue to compose
In this scenario, the EA tool holds authoritative facts (the application inventory, the technology landscape, the integration map, the organizational structure, the lifecycle state of every asset, and the relationships between assets) while the Codex provides the semantic reasoning layer, the validation logic, the projection rules, and the operating workflows that turn those facts into governed decisions. The Codex reads from the EA tool through MCP or equivalent interfaces, applies interpretation and checking, and returns outputs that the EA tool stores or references.
This is the working configuration for most enterprises adopting the Codex pattern today because it respects the practical reality that the EA tool remains a significant data-governance investment.
The worked examples throughout this chapter operate in this mode: the principles, standards, and references live in the Git repository as skills, they read LeanIX or Ardoq fact sheets via MCP, they apply the validation and projection logic that neither tool hosts natively, and they produce the catalogs, matrices, and diagrams that governance forums consume. The EA Council from Chapter 4 owns the Git repository and the governance workflow, while the EA tool owns the data integrity and the operational interfaces.
The stability of this scenario depends on whether the EA tool vendors keep their MCP surface and their metamodel extensibility open enough that the Codex layer above them remains viable.
The evidence suggests they will, because the vendor incentive runs the same direction: an EA tool whose data is easily consumable by external AI agents is more valuable than one that locks data behind proprietary interfaces. Both Ardoq’s publicly documented MCP guidance and SAP’s published AI-agent sample code point to active investment in making the platform a first-class data source for external AI tools, not only a host for internal ones.
13.4. Side-by-side assessment
The 3 scenarios above are not equally mature, not equally likely, and not equally suitable for every enterprise context as you can see on the table below.
- Scenario 1 fits regulated enterprises, SAP-anchored landscapes, and heavily-invested LeanIX or Ardoq customers with existing governance maturity. Its strength is the mature subscription and workflow surface the EA tool already provides, and the low adoption friction of building on an existing investment. Its weaknesses are the metamodel evolution required to host typed principles and skills as first-class objects, and the capability to handle architecture as code natively. The direction of travel is accelerating, as both Ardoq and LeanIX ship quarterly AI-governance increments.
- Scenario 2 fits challenger enterprises, greenfield divisions, and technology-forward organizations with strong data platforms. Its strength is full architectural flexibility, no vendor lock-in, and alignment with engineering practice. Its weakness is the build-versus-buy burden, which is significant for regulated and large enterprises and is itself the reason the layer-by-layer rating below marks four out of five layers as Partial. The direction of travel is accelerating among challengers, awaiting a consolidation event or major reference deployment.
- Scenario 3 fits most enterprises adopting the Codex pattern incrementally. Its strength is that it preserves the EA tool investment while gaining Codex benefit. Its weakness is integration-layer complexity, with two governance surfaces to keep consistent. It is the dominant near-term configuration and will gradually shift toward scenario 1 or scenario 2 as vendor or challenger maturity lands.
| Dimension | Scenario 1: EA tool dominant | Scenario 2: Codex absorbs EA tool | Scenario 3: Two compose |
|---|---|---|---|
| Best fit | Regulated enterprises; SAP-anchored landscapes; heavily-invested LeanIX / Ardoq customers with governance maturity. | Challenger enterprises; greenfield divisions; technology-forward organizations with strong data platforms. | Most enterprises adopting the Codex pattern incrementally. |
| Strength | Mature subscription and workflow surface; low adoption friction on an existing investment. | Full architectural flexibility; no vendor lock-in; alignment with engineering practice. | Preserves the EA tool investment while gaining Codex benefit. |
| Weakness | Metamodel evolution needed to host typed principles and skills as first-class objects; limited architecture-as-code. | Build-versus-buy burden, significant for regulated and large enterprises; four of five layers rated Partial. | Integration-layer complexity; two governance surfaces to keep consistent. |
| Direction of travel | Accelerating: Ardoq and LeanIX ship quarterly AI-governance increments. | Accelerating among challengers; awaiting a consolidation event or major reference deployment. | Dominant near-term configuration; will gradually shift toward Scenario 1 or 2 as vendor or challenger maturity lands. |
Figure 12: Scenario comparison table.
The side-by-side summary in Figure 12 above is useful for positioning, but the more rigorous comparison asks where each scenario falls short and why. The rating in Figure 13 below uses a four-level scale:
- Now means the capability is production-ready today in shipped features of the named vendors or technologies.
- Partial means some components of the layer are shipped and others are missing.
- Roadmap means the missing components are publicly announced, in beta, or on a near-term product roadmap.
- Gap means the missing components are not on a roadmap, and in some cases are structurally hard because they are architecturally mismatched to the platform’s core design.
| Rating | Meaning |
|---|---|
| Now | Production-ready today in shipped features of the named vendors or technologies. |
| Partial | Some components of the layer are shipped and others are missing. |
| Roadmap | Missing components are publicly announced, in beta, or on a near-term product roadmap. |
| Gap | Missing components are not on a roadmap, and in some cases are architecturally mismatched to the platform's core design. |
Figure 13: Summary rating across the five layers.
Layer 1 is “Now” across all three scenarios and carries no partial or gap content worth detailing (MCP servers are at general availability). The comparison therefore concentrates on Layers 2 through 5, where the scenarios diverge.
Layer 2. Enterprise semantic substrate.
- In scenario 1, the EA tool does not manage semantics. It holds capability maps and organizational models well, but it cannot host a shared ontology, typed enterprise intent, or L1-L4 Council delegation as first-class objects. These are not roadmap items; they require a semantic backend the fact-sheet database was not designed to support.
- In scenario 2, an ontology comes naturally with GraphDB or Ontotext, which is a strength of triplestore platforms.
- Scenario 3 composes the two: the EA tool carries the structural data; the Codex carries the semantic skills.
Layer 3. Architectural artifacts.
- In scenario 1, the EA tool ships the four primitives as descriptive objects but cannot execute them as runtime policies. Integrating a policy engine such as Rego, or hosting user-authored AI skills that validate artifacts on demand, is structurally difficult because the platform does not let customers add their own skills or policies into its runtime. An external sidecar is possible but sits outside the product. Neither vendor has announced this capability.
- In scenario 2, templates and policy authoring are first-class, though execution still needs assembly.
- Scenario 3 composes the two: artifact metadata stays in the EA tool; executable policies live in the Codex.
Layer 4. Operating model.
- In scenario 1, the EA tool supports modeling-time governance (decision records, surveys, approvals) but not spec-driven engineering governance (BMAD, Council L1-L4 delegation, weighted AI-risk compliance scoring, pull-request review). This is a pattern mismatch: the platform was built for data curation, not for spec-driven workflow.
- In scenario 2, solution like ArcKit ships the spec-driven workflow natively.
- Scenario 3 composes the two: portfolio-level governance in the EA tool, spec-driven governance in the Codex. The difficulties lie in creating and maintaining a working integration and the coherence of the two.
Layer 5. Deliverables.
- In scenario 1, the EA tool regenerates deliverables from its own data but not from external Codex content, because it cannot host the typed skills that drive Codex projections.
- In scenario 2, native tools (Peaqview, ArcKit) produce deliverables from their own content; the data-platform path needs a custom BI layer.
- Scenario 3 composes the two: native deliverables from the EA tool, custom projections from the Codex.
13.5. Synthesis and Recommendations
A feature gap that ships in the next release is different from an architectural mismatch that would require a platform rewrite, and the layer-by-layer detail in Figure 14 below makes that distinction explicit.
| Codex Layer | Scenario 1: EA tool dominant | Scenario 2: Codex absorbs EA tool | Scenario 3: Two compose |
|---|---|---|---|
| Layer 1: Data interface (MCP) | Now | Now | Now |
| Layer 2: Enterprise semantic substrate | Gap | Now | Now |
| Layer 3: Architectural artifacts & policy | Gap | Partial | Now |
| Layer 4: Operating model | Gap | Partial | Now |
| Layer 5: Deliverables | Partial | Partial | Now |
Figure 14: Scenarios compared against the five EA Codex layers.
- The current trend is clearest on the data interface: every major EA tool now has MCP either in general availability or on the near-term roadmap, and this is the single piece of vendor behavior that makes the Codex pattern tractable at all. The less clear trend is where the principle-and-standard authoring layer lands.
- Scenario 1 has one Gap layer (Layer 4) and three Partial layers, with two of those Partials (ontology and policy engine) architecturally mismatched to the platform core. These are not schedule gaps; they require platform re-architecture.
- Scenario 2 has four Partial layers reflecting a multi-vendor assembly burden of twelve to eighteen months.
- Scenario 3 has five Now layers because each piece lives where it natively belongs: EA tool for portfolio, workflow, and visualization; Codex for executable validation, typed intent, ontology, and operating-model skills.
For architects making planning decisions in 2026, the honest recommendation is to adopt the Codex pattern in scenario 3 form (EA tool plus Git-distributed Codex) regardless of which longer-term scenario the enterprise bets on, because the scenario 3 configuration is productive immediately, preserves optionality toward either absorption direction, and uses interfaces that all three scenarios depend on. At the same time, EA tool vendors will adapt their roadmap to close the gaps in the next 18 to 24 months. Nevertheless, the structural gaps in Layer 2 ontology and Layer 3 policy engine are platform rewrites unlikely to land in that window.
Scenario 2 will be the preferred scenario for data and AI driven companies, looking for soverign solutions and data safe harbor. The landscape will mature through challenger deployments and open-source toolkits growth; multi-vendor assembly remaining the principal constraint. The pace of innovation from AI start-ups and open-source contributors, can change the landscape dramatically before the end of 2026.
14. Sources
- The Open Group, TOGAF Standard, Architecture Content Framework. Reference for the building-block vocabulary used in this chapter (architecture principles, technology standards, reference architectures, blueprints) and the deliverable forms (catalogs, matrices, diagrams). https://pubs.opengroup.org/togaf-standard/
- William El Kaim, “From Vibes to Flow: Building the Enterprise Codex for Agentic AI”, Medium, February 2026. The framing of the Codex as the structured embodiment of collective architectural knowledge that AI activates by SDLC stage. https://el-kaim.com/from-vibes-to-flow-building-the-enterprise-codex-for-agentic-ai-242766cfc810
- William El Kaim, “From Vibes to Codex to Claw: Architecture enters the Edge era”, Medium, February 2026. The progression from prompting to codex to local-first agents that situates the Codex within a broader cognitive infrastructure narrative. https://el-kaim.com/from-vibes-to-codex-to-claw-architecture-enters-the-edge-era-f52d5087c2b5
- GOV.UK Service Standard. Public example of a governance corpus organized as explicit, shared, assessable expectations rather than prose. https://www.gov.uk/service-manual/service-standard
- Backstage. Open-source software catalog and developer portal showing the typed-catalog pattern at scale. https://backstage.io/
- Crossplane. Declarative resource composition for cloud infrastructure, illustrating the projection-over-typed-content pattern in the infrastructure domain. https://www.crossplane.io/
- Anthropic Skills documentation. The SKILL.md schema, skill composition pattern, and Claude Desktop / Claude Code distribution mechanisms used as the packaging form for the Codex described in this chapter. https://docs.claude.com/
- Open Policy Agent (OPA) and Rego. Policy-as-code engine cited in the principle-validation discussion and used in the ACME Pharma worked example. https://www.openpolicyagent.org/
- Model Context Protocol. The integration contract through which the Codex skills read enterprise data from the EA tool. https://modelcontextprotocol.io/
- Ardoq, AI Gateway (MCP Server) announcement and Q1 to Q4 2025 / Q1 2026 AI Roundups. Public evidence of the incumbent-EA-tool-absorbs scenario, including MCP GA in Q3 2025 and the AI Lens solution for AI portfolio governance. https://www.ardoq.com/blog/ea-ai-mcp and https://www.ardoq.com/blog/q1-2026-ardoq-ai-roundup
- SAP LeanIX, MCP Server for SAP LeanIX solutions announcement and AI Agent Hub announcement. Public evidence of the SAP-ecosystem path for the incumbent-absorbs scenario. https://www.leanix.net/en/blog/mcp-server-for-sap-leanix-solutions and https://www.leanix.net/en/blog/sap-leanix-announces-launch-of-ai-agent-hub-and-key-industry-partnerships
- Peaqview, AI-native enterprise architecture platform. Public evidence of the challenger path for the Codex-absorbs scenario, with native process mining and over one hundred MCP tools. https://www.peaqview.com/
- ArcKit, open-source enterprise architecture governance toolkit. Public evidence of the open-source-toolkit path for the Codex-absorbs scenario, with 68 AI-assisted commands across Claude Code, Gemini CLI, GitHub Copilot, Codex CLI, and OpenCode CLI. https://arckit.org/ and https://github.com/tractorjuice/arc-kit
- Neo4j, Databricks and Snowflake integrations. Public evidence of the graph-overlay path for the Codex-absorbs scenario, providing the semantic layer that lakehouses and warehouses lack. https://neo4j.com/partners/databricks/
- OnToText, Enhance LLM with a Knowledge Graph. https://www.ontotext.com/