Earlier chapters developed the spec-driven argument for capabilities, decisions, specifications, controls, and delivery, showing how enterprise architecture must move from periodic document production to continuous, semantic, executable governance. That argument applies to data with higher urgency than to the other domains, because the consumption face for enterprise data is shifting from humans browsing BI dashboards to agents reasoning over knowledge structures, and the cost of ambiguity, unenforced contracts, and semantic drift rises sharply once agents are in the consumption path.
The shape of the argument is that a small set of architectural artifacts must carry data meaning from business intent to operational enforcement: the business object as a semantic anchor governed in the Codex, the data product as the owner-bound and contracted realization of one or more business objects, the data contract as the executable specification that the platform enforces, the semantic layer and ontology as the architectural surface through which meaning reaches agents, and the context data product as the pattern that makes data actionable for agentic consumption rather than merely readable by it.
The chapter develops each of these artifacts and shows how they connect to the Codex and to the MCP distribution layer that carries them to consumers.
1. The data management gap in most EA practices
Enterprise architecture has always claimed data as part of its scope.
- Every major framework includes a data layer: TOGAF defines data entities and logical data components, ArchiMate distinguishes business objects, data objects, and artifacts, and DoDAF carries a data and information viewpoint.
- Every mature EA team has produced conceptual data models, information maps, and data entity catalogs, and every large enterprise transformation has included a data workstream.
And yet when a senior engineer connects an AI agent to one of those same enterprises, something recognizable fails. The agent cannot answer business questions reliably because it pattern-matches on column names, picks the wrong definition of revenue, misinterprets regional codes, and returns audit-failing answers with high confidence. The problem is not that the organization lacks data; it is that the enterprise never made its data semantics, its data ownership, and its data quality machine-consumable in a form that downstream consumption, human or agentic, can trust.
Traditional EA modeled data without specifying it in a form machines can execute, and governed data without tying governance to delivery:
- The business object on an ArchiMate diagram is not readable by a pipeline.
- The data entity in a TOGAF catalog is not enforced by a deploy.
- The conceptual data model in a slide deck does not tell an agent whether “customer” in the CRM means the same thing as “customer” in the ledger.
A data architecture of this kind is documentation rather than a control system.
2. Why traditional data architecture fails for agentic execution
The history of enterprise data architecture can be read as three generations, each answering a weakness of the previous one.
- The centralized data warehouse of the nineteen-nineties and early two-thousands solved reporting consistency.
- The data lake and lakehouse of the twenty-tens solved storage economics and analytical flexibility.
- The data mesh and data-product turn of the late twenty-tens solved the organizational bottleneck by pushing ownership to the domains that understood the data.
Each generation produced real value, yet none produced artifacts that an AI agent can consume without heavy prompting, retrieval scaffolding, and a measurable hallucination rate. The failure mode is consistent across generations:
- Semantics are implicit in analyst knowledge rather than explicit in machine-readable specifications: a field named active_flag means different things in different domains, and the difference lives in someone’s head.
- Quality commitments are inherited by convention rather than enforced by contract. Two systems claim to carry the same customer, with no authoritative resolution between them.
- Ownership is organizational rather than architectural, which means that a data consumer cannot tell who will fix a broken field or how long the fix will take.
The shift to data products under a mesh model improved the ownership story, because a data product has a name, an owner, a domain, and a stated purpose, and the architectural quantum became the product rather than the table. What rarely improved was the semantic substrate underneath. Most mesh implementations remain federated collections of tables with owner labels, where the meaning of the fields, the relationships across domains, and the quality commitments are still implicit, still social, and still recovered through tribal knowledge.
Agentic execution makes this gap intolerable. Gartner’s research frames the point clearly: by twenty-thirty, roughly half of enterprise AI agent deployment failures will trace back to insufficient governance and interoperability. The model is not the scarce resource; the structured, machine-readable context that lets the model reason safely over enterprise data is.
An agent with a strong model and weak data context will be confidently wrong, whereas an agent with a modest model and strong data context can be useful, bounded, and auditable. The concrete failure pattern is one every architect recognizes: a risk score documented as a numeric value between one and ten with no indication of direction, a region code EM that includes frontier markets in one division and excludes them in another, or a revenue figure that is bookings in one report and GAAP-recognized revenue in another.
Ademola’s recent writing on context data products makes the case sharply: the traditional data product, even when well owned and well documented, was designed for a human analyst who could repair these gaps through context and judgment, whereas an agent cannot repair them and therefore hallucinates.
The architectural lesson is that the data product as it stands today in most mesh implementations is necessary but not sufficient, having solved the organizational problem without solving the semantic and consumption problem.
3. The specification chain applied to data
The conceptual chain the book has developed for architecture in general carries directly into data:
- Intent defines what the enterprise wants
- Decision closes the design space
- Specification formalizes the closed decisions
- Execution instantiates the specification in running systems
- Feedback updates the decisions when reality diverges.
What changes for data is the set of artifacts that carry each stage.
- Intent for data is expressed at the capability level rather than at the field level. A clinical operations capability might declare that it needs a canonical view of site activation status across all active trials, with near-real-time freshness during recruitment and full lineage to regulatory source documents. A finance capability might declare that its consolidated revenue view must reconcile to the general ledger within a fixed tolerance and must preserve the distinction between bookings, invoiced revenue, and recognized revenue. These are statements about why the data exists and what must be true for it to serve its capability, not data schemas.
- Decision for data records the consequential choices that turn intent into a governed plan: whether to hold one canonical customer product for the group or a federated set with a conformance contract, whether master data lives in a dedicated MDM platform or is produced by a lead domain and consumed by others, and whether the quality regime is preventive at the producer or detective at the consumer. These choices carry consequences for cost, delivery tempo, and regulatory posture, and they must be recorded as decisions in the Codex with context, rationale, and supersedes relations, because a future architect will need to understand why the choice was made before amending it.
- Specification for data assembles the decisions into artifacts that systems consume. A business object specification states what the enterprise means by a named concept with identity rules, versioning, and governance. A data product descriptor states how a realization of one or more business objects is packaged, owned, and exposed. A data contract states what the producer commits to and what the consumer is permitted to rely on, while an ontology mapping connects the shape to the semantic layer and a policy file expresses invariants that must hold at deploy and at runtime. These artifacts are versioned, linked, and validated together.
- Execution and feedback for data follow the same pattern the spec-driven frame applies to applications and infrastructure. The platform provisions the data product from the contract, registers it in the catalog, stands up the quality monitors the contract declared, exposes the semantic mapping, and publishes discovery and access endpoints including MCP servers for agent consumption. Contract validation gates delivery in CI. Quality monitors run in production, and breaches trigger the escalation paths the contract defined. The feedback loop then flows through the quality metrics the contract exposed, the consumption patterns the semantic layer recorded, and the confusion patterns the agents revealed when they misread a field. When those signals reach the decision log, a field agents consistently misread is read as a signal that the ontology is underspecified, not that the agent is inadequate.
The difference between this and another data governance framework is one of mechanics rather than aspiration. Each stage produces a typed, versioned artifact under change management. Those artifacts are linked to one another through Codex relations, and every downstream consumer (pipeline, catalog, semantic layer, MCP server) reads from that linked source rather than from a locally maintained copy. Coherence is not recovered through periodic reconciliation because the artifacts were coherent when they were written.
Figure 1 lays out the chain visually, in the same layered form used to describe the broader operating model in earlier chapters.
- At the top sits data intent at the capability level.
- That intent commits to meaning through the business object in the Codex.
- The business object in turn is realized by a data product, which is itself an owner-bound and contracted unit.
- The data contract is where the product’s commitments take executable form.
- The semantic layer binds both the business object and the contract’s field-level semantics into a queryable ontology.
- Context extensions and MCP exposure carry that ontology-grounded product into agent reach.
- A feedback band runs along the bottom, so that quality drift, agent confusion patterns, and usage telemetry return to the Codex as updates to decisions, contracts, and ontology bindings. The rest of the chapter walks through each of the five artifact layers in turn.
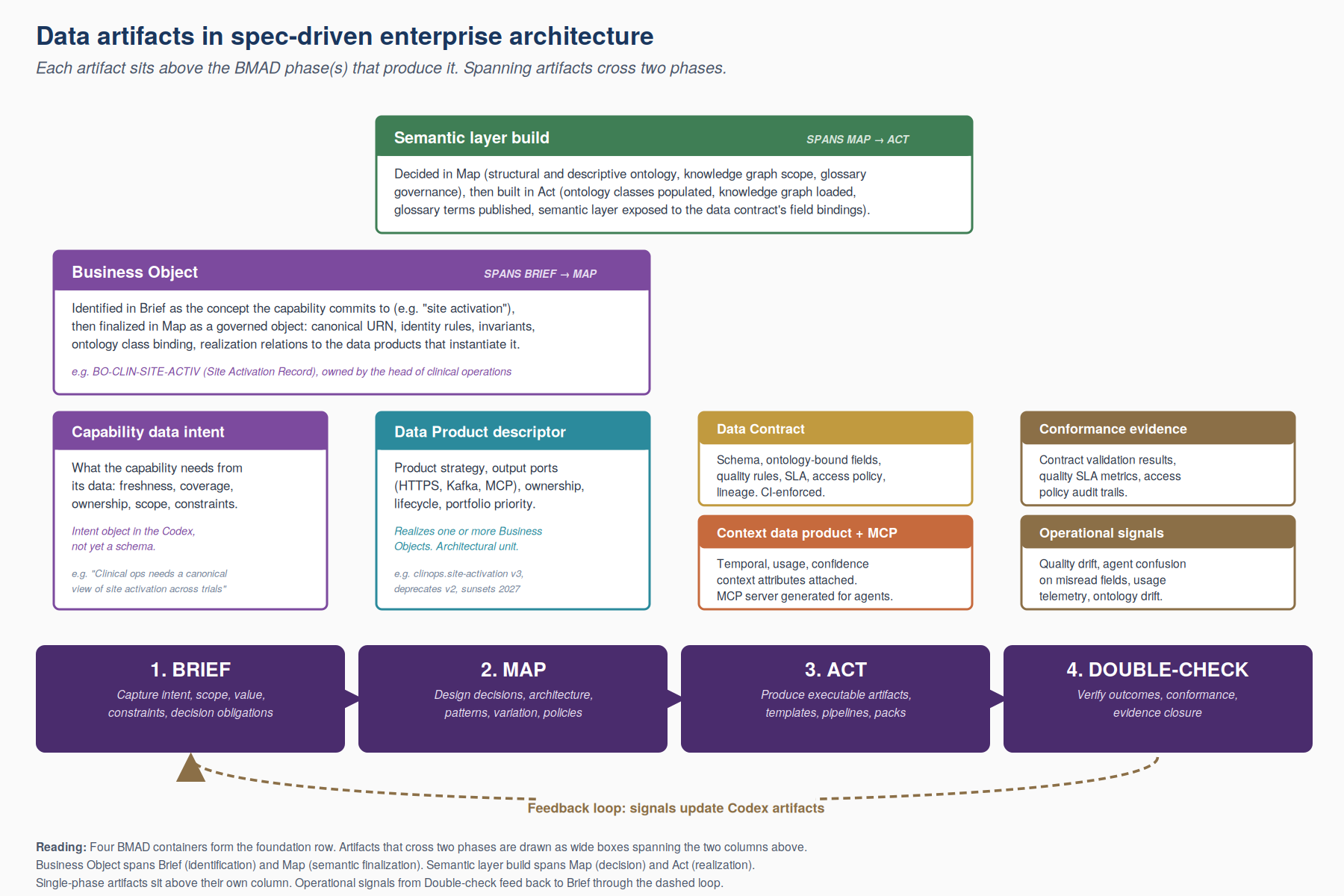
Figure 1: The specification chain (BMAD) applied to data
4. The business object as semantic anchor
The ArchiMate definition of a business object as an important informational concept in which the business thinks about a domain is not wrong so much as incomplete. It works for producing diagrams and for aligning terminology. It does not work for governing meaning at a scale where machines consume the definitions. The spec-driven frame extends the business object from a diagram element into a governed object in the Codex, with identity, semantics, ownership, lifecycle, and explicit realization relations to data products.
The promotion matters because the business object is where the enterprise commits to what it means when it says “customer,” “site,” “product,” or “case.” Without that commitment recorded as a versioned object, each downstream artifact ends up inventing its own interpretation, and semantic fragmentation becomes the predictable outcome. The business object is the upstream semantic commitment that constrains all downstream interpretations.
4.1. Codex fragment defining a business object
Figure 2 shows a Codex fragment defining a business object. Its shape is worth pausing on before moving to the code:
- Identity and governance metadata appear alongside the name, so the object is owned and changeable under rules rather than declared and forgotten.
- Semantic definitions reference the enterprise ontology rather than relying on free-text descriptions, so meaning is resolvable by a machine and not only by a reader who happens to know the domain.
- Realization relations point to the data products that instantiate the object, and the trace from meaning to running system therefore becomes explicit rather than something recovered each time someone asks.
apiVersion: ea.codex/v1
kind: BusinessObject
metadata:
id: BO-CLIN-SITE-ACTIVATION
name: site-activation-record
title: Site Activation Record
status: approved
version: "3.0"
owner: head-of-clinical-operations
spec:
statement: >
A durable record of the activation state of an investigator site
for a specific clinical study, including the regulatory, operational,
and contractual preconditions required for enrollment to begin.
domain: clinical-operations
classification: restricted
governanceOwner: clinops-data-council
identity:
canonicalIdentifier: "urn:acme:site-activation:{studyId}:{siteId}"
versioningRule: monotonic-integer
supersedesPolicy: keep-with-successor-link
semanticMapping:
ontologyClass: clinops:ActivationEvent
ontologyVersion: "2026.1"
glossaryTerm: site-activation
governance:
changeAuthority: clinops-data-council
reviewCadence: quarterly
impactClassification: regulated
semanticRules:
- id: SR-SA-001
type: cross-attribute
rule: activation.requiresRegulatoryApprovalEvidence == true
severity: blocking
- id: SR-SA-002
type: temporal
rule: activation.effectiveDate >= study.firstRegulatoryApprovalDate
severity: blocking
realizedBy:
- DP-CLINOPS-SITE-ACTIVATION-V3
supportedCapabilityRefs:
- CAP-CLIN-SITE-SELECTION
- CAP-CLIN-SUBMISSION-MANAGEMENT
associatedDecisions:
- DEC-CLIN-058
- DEC-CLIN-073Figure 2: Site Activation business object specification
- The canonical identifier in the artifact above expresses identity as a deterministic rule rather than as a free-text suggestion, so that any pipeline or agent can construct a valid identifier without asking the owning team.
- Versioning rule and supersedes policy make the evolution behavior of the object explicit, so that a consumer who reads a record at version three knows that version two is still retrievable and that the link between them is preserved.
- The semantic mapping binds the business object to an ontology class in a named version, which is the hook that makes this object consumable by the semantic layer and by MCP-exposed agent tooling.
- The invariants are not descriptions but statements that downstream specifications must respect and that validation logic can evaluate.
- The realization relation names the data product that instantiates this business object, so that a change to the business object schema can propagate to the data product change management process.
The distinction between business object, data object, and data product is worth making explicit, because these terms collapse into each other in most practices and the collapse is the source of the documentation-only trap the spec-driven frame is designed to escape.
- The business object is the enterprise semantic commitment. It lives in the Codex, is owned by the capability leader, and governs meaning.
- A data object, in the ArchiMate sense, is the technical passive structure that expresses the meaning as a shape suitable for automated processing.
- The data product is different again: it is the operational realization, bound to an owner, packaged by a contract, exposed through defined interfaces, and accountable for delivering the value the capability required.
4.2. Aggregating observed semantics is not the same as certifying approved semantics
The taxonomy above presumes that the enterprise can name where its approved semantics live. That presumption is now contested. This chapter argued that semantic governance must be anchored in typed, owned, machine-readable definitions. That argument now meets a competing claim from the cloud-native data infrastructure space. Google Cloud Next ’26 announced Knowledge Catalog as part of the Agentic Data Cloud, with bidirectional federation to SAP, ServiceNow, Salesforce, and Workday in preview. Reference: https://cloud.google.com/blog/topics/google-cloud-next/welcome-to-google-cloud-next26. Microsoft, Databricks, Snowflake, and Atlan offer adjacent positions. Each of these tools claims to be the place where enterprise semantics live.
The claim is partially true, and the partial truth matters. Knowledge Catalog and its peers aggregate observed semantics. They harvest measure definitions from BigQuery, dimensions from LookML, attributes from SAP master data, fields from Salesforce objects. They expose the harvested view as a unified semantic layer that agents can query. This is a real capability and it solves a real problem: discovery across heterogeneous systems.
What it does not do is certify whether the harvested semantics agree with what the enterprise architecture has approved. A LookML measure named “active customer” may use a definition that worked for a marketing dashboard three years ago and that a new pharmacovigilance regulation has since invalidated. A BigQuery measure for “adverse event count” may aggregate over a filter that excludes regional variants the FDA expects to see included. The catalog will faithfully aggregate these definitions. It will not flag that they conflict with the Codex.
The Codex and the catalog therefore play different roles. The catalog is the aggregator of observed semantics. The Codex is the certifier of approved semantics. The two must coexist, and the coexistence requires an explicit bridge.
The Codex provides that bridge through a proposed extension to ea.codex/v1 named SemanticConformanceCheck. The kind declares an observable term, the approved Codex definition with its regulatory anchors, the observed sources where the term is harvested (agents, data products, knowledge catalogs, generated semantic models), the drift thresholds (semantic, structural, lexical), the measurement method, the frequency, and the action on drift.
Figure 3 below shows a check for the term adverse-event in the pharmacovigilance domain.
# Proposed extension to ea.codex/v1 for semantic conformance checks.
# SemanticConformanceCheck is not a typed kind in canonical v1.1.0; ACME Pharma uses
# it as a local Codex extension to bridge between observed semantics (catalog, agent,
# data product) and the Codex's approved definition. The closest canonical kinds are
# BusinessObject (which defines approved semantics) and FitnessFunction (which
# evaluates rules at PR time).
apiVersion: ea.codex/v1
kind: SemanticConformanceCheck
metadata:
id: SCC-PV-001
name: pv-adverse-event-conformance
status: approved
domain: pharmacovigilance
owner: pharmacovigilance-domain-lead
spec:
term:
canonical: adverse-event
ontologyRef: ontology://pharmacovigilance/adverse-event
approvedDefinition:
statement: >
Any untoward medical occurrence in a patient or clinical investigation
subject regardless of relatedness to the product. Includes lack of
efficacy where regulatory frameworks require reporting.
sourceRefs:
- { framework: ICH-E2A }
- { framework: EMA GVP Module VI }
- { framework: FDA 21 CFR 314.80 }
version: "3.2"
approvedDate: "2026-01-15"
observedSources:
- { type: agent, ref: AGENT-PV-TRIAGE-001, observationMethod: prompt-output-extraction, weight: 1.0 }
- { type: knowledge-catalog, ref: KC-EXTERNAL-PV-DOMAIN, observationMethod: semantic-model-fetch, weight: 0.7 }
- { type: data-product, ref: DP-PV-TRIAGE-OUTPUT-V1, observationMethod: schema-annotation-read, weight: 1.0 }
driftThresholds:
semantic: { method: embedding-cosine, threshold: 0.85, severityOnViolation: warning }
structural:
method: required-attributes-present
requiredAttributes: [regulatoryFrameworkApplicable, relatednessJudgmentRequired]
severityOnViolation: blocking
actionOnDrift:
severityLevels:
- { level: warning, action: notify-domain-lead, slaHours: 48 }
- { level: blocking, action: pause-agent, slaHours: 4, humanGate: pharmacovigilance-domain-lead }
autoRemediation: { enabled: false, reason: regulatory-domain-requires-human-review }Figure 3: Pharmacovigilance conformance check (SCC-PV-001)
The OPA package eacodex.semantic_conformance enforces seven rules. Three are blocking: blocking-severity actions require a human gate; auto-remediation must be disabled in regulated domains; an observed source of type agent or data-product must be present, so the check is operationally measurable. The remaining four are warnings or informational.
The architectural posture this enables is precise. The Codex retains authority over what enterprise terms mean. The catalog retains its function as the discovery surface across heterogeneous systems. The conformance check is the explicit, governed mechanism that asks the question no aggregator can answer for itself: are the observed semantics consistent with what we have approved.
This posture is also the foundation for the principles introduced in the next section. DATA-005 Zero-Copy Governance establishes that the Codex centralizes meaning rather than data. DATA-006 Data Sovereignty Classification constrains where data may legitimately reside. The conformance check is what makes both principles operational: meaning is centralized in the Codex; whether the catalog reflects that meaning is verified continuously rather than presumed.
5. The data product as specified realization
If the business object is where semantics are committed, the data product is where those semantics are operationalized.
The data mesh literature frames the data product as an architectural quantum, the smallest independently deployable unit that combines the data, the metadata, the code, the infrastructure, and the governance required to serve a consumer.
The spec-driven extension adds two requirements: the data product must declare which business objects it realizes so that semantic traceability is explicit, and the data product must be defined by a specification that can be validated, deployed, and enforced as code rather than by a wiki page describing what the team intends.
Public standards have converged on this direction:
- The Open Data Product Specification (ODPS), under the Linux Foundation, provides a vendor-neutral, machine-readable metadata model that defines what a data product is, how it is described, how its quality commitments are monitored as code, how its pricing and access plans are expressed, and how it connects to business intent through a dedicated product strategy object. Adopters include BASF, NATO, Migros, Alation, and FIWARE.
- The Open Data Mesh Data Product Descriptor Specification pursues a similar goal with a different emphasis, focusing on the decomposition of a data product into interface components and internal components.
The practical value of these standards for enterprise architecture is that they give architects a shared shape in which to specify data products without reinventing metadata models. A data product descriptor becomes a Codex object the same way that an intent specification or a capability specification does. It can be reviewed, versioned, linked to decisions, linked to controls, and projected into catalogs, platforms, and agent-facing discovery endpoints.
5.1. Data product description in the codex
Figure 4 shows a data product descriptor written against a subset of the Open Data Product Specification shape. It realizes the business object declared in the previous section. The reader should notice how much of what is traditionally scattered across wiki pages, data catalogs, and ticket queues is now stated as structured metadata that the platform can process.
apiVersion: ea.codex/v1
kind: DataProductContract
metadata:
id: DP-CLINOPS-SITE-ACTIVATION-V3
name: clinops-site-activation-v3
status: approved
version: "3.0"
domain: clinical-operations
spec:
businessObject: BO-CLIN-SITE-ACTIVATION
owner:
domain: clinical-operations
contact: clinops-data-platform-team
purposes:
- site-activation-monitoring
- regulatory-readiness-evidence
- investigator-onboarding-coordination
jurisdiction:
primary: global
allowedRegions: [EU, US, APAC]
interfaces:
- pattern: governed-api
endpoint: port-read-snapshot
schemaRef: CT-DP-SITE-ACTIVATION-SNAPSHOT-V3
protocol: https
accessPattern: pull
- pattern: event-stream
endpoint: port-event-stream
schemaRef: CT-DP-SITE-ACTIVATION-EVENTS-V3
protocol: kafka
accessPattern: subscribe
- pattern: semantic-retrieval
endpoint: port-mcp
schemaRef: CT-DP-SITE-ACTIVATION-MCP-V3
protocol: mcp
accessPattern: agent-tools
productStrategy:
businessIntent: INT-CLIN-2026-004
outcomes:
- metric: activated-sites-within-plan-window
target: ">= 78%"
- metric: consumer-trust-score
target: ">= 4.3/5"
inputPorts:
- source: ctms-primary
type: application-database
- source: etmf-regulatory
type: document-repository
qualityAttributes:
declarative:
- dimension: completeness
target: ">= 99.5%"
- dimension: freshness
target: "< 15 minutes"
- dimension: consistency
target: "zero duplicate canonical identifiers"
executable:
runtime: soda-core
ruleset: clinops.site-activation.v3.soda.yaml
semanticExposure:
ontologyBinding: clinops:ActivationEvent
knowledgeGraphEndpoint: kg.acme-clinops.internal/v1
contextDimensions: [semantic, temporal, usage, confidence]
lifecycle:
introduced: "2024-11-15"
deprecates: DP-CLINOPS-SITE-ACTIVATION-V2
plannedSunset: "2027-06-30"
portfolioPriority: HighFigure 4: Site Activation data product descriptor
- The product strategy block is the most architecturally consequential part of the specification. It binds the data product to an enterprise intent and to measurable outcomes. A data product that cannot declare which intent it serves is, by definition, not governed by architecture; it is an artifact produced for its own sake.
- The interfaces block makes consumption patterns explicit and attaches each port to a specific contract.
- The quality block combines a declarative target with an executable ruleset, which is the operational form of the data contract’s quality commitments.
- The semantic exposure block names the ontology binding and the knowledge graph endpoint, allowing the semantic layer to build a unified view over this product without recomputing meaning from column names.
- The lifecycle and portfolio priority blocks let the architecture team manage the data product portfolio with the same discipline applied to applications.
What this specification does not contain is equally important.
- Field-level schema definitions live in the data contract,
- ACL lists are derived from the contract’s access plans,
- Pipeline DAGs remain implementation details owned by the product team.
The discipline is separation of concerns, where the data product descriptor describes what the product is and how it is governed, the contract describes what the producer commits to and what the consumer may rely on, and the implementation describes how the product is built.
6. Zero-Copy and Sovereignty as Distinct Principles
The shift to cross-cloud lakehouse, federated catalogs, and Apache Iceberg as the de facto open table format has compressed the time available to architects to think about where enterprise data actually lives. Bidirectional catalog federation reached preview at Google Cloud Next ’26, and equivalent mechanisms exist in adjacent ecosystems. Reference: https://cloud.google.com/blog/topics/google-cloud-next/welcome-to-google-cloud-next26. The capability to query data in place across clouds is no longer an architectural ambition. It is operational reality for the next budget cycle.
This reality stresses two assumptions that traditionally lived together unexamined in enterprise architecture: that governance requires physical centralization, and that data location is largely an architectural decision. Both assumptions are wrong, but they are wrong in different ways and require two distinct corrective principles.
The first assumption is wrong as an architecture claim. Modern enterprise data is irrevocably distributed across multiple clouds, multiple SaaS systems, multiple partner platforms, and multiple on-premise systems. A program that promises to physically centralize all enterprise data has not delivered in any large enterprise context within reasonable cost or timeline. The claim is also unnecessary: federated query, replication for resilience, and zero-copy access patterns make data accessible without requiring its consolidation. The Codex therefore declares this in DATA-005 Zero-Copy Governance:
Enterprise architecture governs meaning, decisions, policies, and usage contracts. It does not require data to be physically centralized. Data products may reside in any approved location and may be accessed through federation, replication, or zero-copy query, provided the access mode satisfies the relevant data contracts and sovereignty constraints.
The principle has several implications operationalized through Codex artifacts:
- Data location decisions become operational rather than architectural.
- DataProductContract artifacts must declare their locations explicitly via spec.locations[].
- DataContract artifacts must declare federation parameters when applicable via spec.federation.
- The Codex retains authority over BusinessObject definitions, DataContract semantics, and DataProductContract ownership.
- External catalog tools aggregate observed semantics and are not authoritative for approved semantics, with SemanticConformanceCheck as the bridge.
The second assumption is wrong as a regulatory claim.
- Data location is not architectural in the sense of being a free choice.
- GDPR, Schrems II, the EU AI Act, US sectoral rules including HIPAA, China PIPL, India DPDP, and various financial sector rules constrain where data may legitimately reside, who may access it, and under which legal mechanisms it may cross borders.
These constraints override otherwise-valid architectural decisions. Without explicit jurisdictional classification on every data product, the constraints are enforced ad hoc, often after a violation has occurred.
The Codex declares the regulatory counterweight in DATA-006 Data Sovereignty Classification:
- Every data product carries an explicit jurisdictional classification.
- Cross-border data flows are governed by regulatory frameworks that may override otherwise-valid architectural decisions.
The Codex enforces classification at the data product level and constrains location and federation choices accordingly.
The two principles can conflict and the conflict is meaningful. A federated query that satisfies DATA-005 may violate DATA-006 if it crosses a jurisdictional boundary without an adequate legal mechanism. When in conflict, DATA-006 prevails. Architecture yields to regulation.
The operational consequence is that DataProductContract.spec.locations[].sovereigntyClass and DataContract.spec.federation.jurisdictionConstraints[] become first-class authoring concerns. The CI pipeline rejects data products without explicit sovereignty class. It rejects cross-jurisdiction flows without documented legal basis. It rejects agent contracts that read EU-residency data while running in non-EU regions without an approved regulatory review recorded as a DecisionRecord.
The reader may notice that DATA-005 and DATA-006 do not yet exist as new kinds. They are instances of the existing ArchitecturePrinciple kind defined in Chapter 6. This is intentional. Principles can carry the architectural claim. A future chapter on sovereignty in this book may justify a dedicated kind such as JurisdictionalPolicy or DataSovereigntyClassification once the structure of jurisdiction-specific rules becomes complex enough to warrant it. For the current state of practice, two well-anchored principles with executable validation logic are sufficient.
The deeper point is that EA must explicitly distinguish architectural posture from regulatory constraint. Conflating them produces governance theater: principles that read like architecture and that ignore the legal frame, or regulatory rules that read like compliance and that ignore the architectural posture they imply. The Codex separates them deliberately. Both are first-class. Both are validated. Neither subordinate to the other.
7. Data contracts as executable specification
The data contract is the point at which the specification becomes enforceable.
A data contract defines the structure, semantics, quality commitments, service-level commitments, and terms of use for a data exchange between a producer and one or more consumers.
The defining property of a contract in the spec-driven frame is that it is expressed as code, versioned under change management, and validated automatically in delivery and operation. It is the equivalent, for data, of an OpenAPI specification for services or a Rego policy for platform admission.
Two open standards have emerged around data contracts and are worth naming because they define the shape architects can expect to see in tooling:
- The Data Contract Specification, maintained by the datacontract-cli community, follows OpenAPI conventions and aims to feel immediately familiar to engineers who have specified APIs.
- The Open Data Contract Standard, developed under an RFC process and now aligning with the broader Open Data Product Specification family, covers similar ground with a different emphasis on SLAs and pricing.
Both express the everything-as-code philosophy, generate machine-readable artifacts (that tools such as Soda, Monte Carlo, Gable, and Data Contract Manager) consume to run contract validation in CI and to run quality monitoring in production.
Figure 5 below is a fragment of the snapshot contract referenced by the data product descriptor above. It is written in a shape compatible with common data contract tooling. The reader should notice how the contract combines schema, semantics, quality rules, and service-level commitments into a single specification that the platform can enforce without an intermediate translation layer.
apiVersion: ea.codex/v1
kind: DataContract
metadata:
id: CT-DP-SITE-ACTIVATION-SNAPSHOT-V3
name: site-activation-snapshot-v3
status: approved
version: "3.1.0"
owner: clinops-data-platform-team
spec:
dataProductRef: DP-CLINOPS-SITE-ACTIVATION-V3
businessObjectRef: BO-CLIN-SITE-ACTIVATION
accessPattern:
pattern: governed-api
endpoint: port-read-snapshot
protocol: https
schema:
format: avro
type: record
name: SiteActivationSnapshot
fields:
- name: canonicalId
type: string
businessObjectAttribute: clinops:ActivationEvent.id
nullable: false
- name: studyId
type: string
businessObjectAttribute: clinops:Study.id
nullable: false
- name: siteId
type: string
businessObjectAttribute: clinops:Site.id
nullable: false
- name: jurisdiction
type: string
businessObjectAttribute: regulatory:Jurisdiction.code
allowedValues: [ISO-3166-1-alpha-2]
nullable: false
- name: activationStatus
type: string
businessObjectAttribute: clinops:ActivationEvent.status
enum: [Pending, ConditionallyActivated, Activated, Suspended]
nullable: false
- name: effectiveDate
type: timestamp
nullable: false
- name: regulatoryApprovalEvidenceRef
type: string
businessObjectAttribute: regulatory:ApprovalDocument.ref
nullable: false
- name: confidenceScore
type: number
businessObjectAttribute: context:ConfidenceScore
minimum: 0
maximum: 1
nullable: false
sla:
freshness: "< 15 minutes"
availability: "99.9%"
incidentResponse: "P1 < 1h, P2 < 4h"
qualityEnforcement:
- check: completeness
threshold: ">= 99.5% over 24h window"
action: block
enforcedBy: soda-core
- check: uniqueness-canonicalId
threshold: "100%"
action: block
enforcedBy: soda-core
- check: freshness
threshold: "< 15 minutes"
action: warn
enforcedBy: soda-core
versioning:
currentVersion: "3.1.0"
compatibilityPolicy: backward-compatible-only
deprecationNoticePeriod: "180d"
semantics:
domainGlossary: clinops-glossary
ontology:
binding: clinops:ActivationEvent
version: "2026.1"
contextDimensions:
temporal:
validFrom: effectiveDate
latestAsOf: snapshot.generatedAt
confidence:
source: confidenceScore
method: source-completeness-weighted
access:
authentication: workload-identity
authorization: opa-policy://clinops/data-access/v2
retentionYears: 10
lineage:
upstream:
- system: ctms-primary
capture: change-data-capture
- system: etmf-regulatory
capture: event-stream
transformations: transformations/clinops-site-activation-v3/Figure 5: Site Activation data contract (snapshot output port)
Each block of the contract has an enforcement path.
- The schema block is validated at every produce, by a schema registry or an inline library. A breaking change fails the producer’s pipeline before deployment.
- The semantics block binds each field to an ontology term and a glossary entry, which is what the semantic layer consumes to expose the product through a knowledge graph.
- The quality rules are compiled into executable checks by tools in the Soda or Monte Carlo family and run both as gates in CI and as continuous monitors in production. A breach triggers the SLA escalation path.
- The access block declares the authentication and authorization mechanism and delegates policy enforcement to an OPA policy referenced by URL, which keeps the contract portable and the policy evolvable.
- The service levels block states the commitments that operational incident response will measure against.
- The lineage block declares the upstream sources and the transformation code path, giving consumers and auditors a stable reference for reasoning about provenance.
A contract of this form is more than documentation. It is an enforceable specification that converts data governance from a periodic review activity into a continuous control activity, in which the architect does not need to chase teams for compliance because the pipeline rejects non-conformant changes, the monitoring stack surfaces quality breaches before consumers notice, and the access system enforces the policy without a ticket. This pattern mirrors what the spec-driven frame has established for other architectural domains, now applied to data.
8. The semantic layer as the AI-consumption face
A well-specified data product with an enforceable contract is a necessary condition for safe consumption but not a sufficient one. Consumption by humans has always relied on an interpretive layer: analysts read documentation, asked colleagues, and built-up tacit knowledge. Consumption by AI agents cannot rely on interpretation because the agent has neither the colleague nor the time to read a wiki. The agent must reason over structured meaning, or it will reason over column names and fabricate plausible answers. The semantic layer is the structural solution to this problem.
The semantic layer has a longer history than the agentic conversation suggests.
- Business intelligence tools have included semantic abstractions for decades, under names such as universe, cube, and metric layer. The modern iteration combines three kinds of structured meaning that older tools did not always separate.
- Analytic semantics define metrics and the formulas behind them, so that gross margin is computed consistently across dashboards.
- Knowledge semantics define entities and their relationships across domains, so that a customer, an order, and a payment are connected in a graph rather than reconstructed by join logic.
- Formal ontology adds the vocabulary and inference rules that let a reasoner infer, for example, that a preferred customer is a customer and that a customer must have at least one account.
Published platforms illustrate the different emphases:
- Palantir Foundry positions its ontology as the operational layer for the organization, binding datasets to real-world entities and acting as the digital twin through which workflows execute and agents’ reason.
- Salesforce’s architecture for the Agentic Enterprise names the semantic layer as a distinct tier above the data layer, built on an enterprise knowledge graph that encodes entities, concepts, definitions, and relationships.
- Atlan positions the active ontology as the backbone and distinguishes ontology-first architectures from schema-first and prompt-first approaches.
- Sema4.ai focuses on letting agents query databases and documents with natural language while honoring governed semantic models
- Timbr.ai provides an SQL-based ontology layer that pushes ontology reasoning into query execution.
The strategies differ in emphasis, but they converge on the same underlying argument: data without explicit, structured semantics is not safely consumable by an agent.
A useful distinction, articulated by Salesforce’s architecture team, separates structural ontologies from descriptive ontologies.
- A structural ontology maps business concepts to data locations, serving as the data atlas that tells an agent where to look when a question names a concept
- A descriptive ontology defines what the concepts mean, including the constraints, rules, and relationships that govern reasoning over them.
An agent grounded in both can find the relevant data and know how to interpret it, while an agent grounded in one but not the other produces answers that are locally correct and globally wrong.
The architectural implication is that the semantic layer is not a bolt-on but a specification surface owned by architecture.
- The business objects defined in the Codex feed the descriptive ontology,
- the data product descriptors feed the structural ontology through their semantic exposure blocks,
- the contracts feed both, because the field-level semantic bindings are the ground-truth mapping from data to ontology.
The semantic layer is the assembly point where these specifications become a unified, queryable, agent-consumable view, and architecture governs the assembly rules, the extension rules, and the conformance criteria. The semantic layer is continuous because the Codex is continuous.
9. Context data products as the differentiator
Even with a well-governed ontology, an agent may still fail on consumption tasks for a reason that has nothing to do with semantics in the narrow sense: the data may lack the context that makes its meaning actionable.
Ademola’s recent formulation of the context data product captures this argument with useful precision. A data product designed for a human analyst was designed on the implicit assumption that the analyst brings context from outside the product, whereas an agent brings none and the context must therefore live inside the product itself.
The agentic setting makes four kinds of context architecturally significant:
- Semantic context defines what a field means in business terms, the surface that the ontology and semantic layer address.
- Temporal context defines when the data was relevant, when it was generated, and when it becomes stale, because an agent answering about current state must distinguish a snapshot from a live feed.
- Usage context records how consumers, human and agentic, have successfully used the product, including common query patterns and known pitfalls, so that a new agent benefits from accumulated institutional memory rather than rediscovering it.
- Confidence context records how reliable the data is for specific decisions, including source completeness, reconciliation status, and quality SLA compliance at read time, which is what allows an agent to refuse or hedge when the evidence is insufficient.
The value of framing these context dimensions as first-class attributes of the data product rather than as addenda to a documentation page is that they then become part of the specification itself, and therefore part of the pipeline, the catalog, and the agent-facing tooling.
- Temporal context stops being a README paragraph and becomes a set of fields on every record, with a corresponding schema extension on the contract.
- Confidence stops being a subjective reputation score and becomes a computed attribute, derived from the quality rules the contract already defined, attached at snapshot time.
- Usage stops being tribal knowledge that someone recovers on request and becomes a queryable structure, built from catalog telemetry and the logs of queries that worked, exposed through the semantic layer as a property of the product itself.
The strategic argument for this investment was articulated clearly at the Gartner Data and Analytics Summit in Orlando in March 2026, where the context layer was repeatedly described as critical AI infrastructure rather than as a convenience. Gartner’s reading of the current market is that Model Context Protocol adoption alone will not rescue enterprises from hallucination problems: the research firm projects that roughly sixty percent of agentic analytics projects relying solely on MCP will fail by twenty-twenty-eight because they lack a consistent semantic layer underneath.
The implication for enterprise architecture is straightforward. As models become commoditized and vendors converge on comparable capabilities, what an enterprise cannot buy off a shelf is its own accumulated context. How it defines customer, product, and risk, what its governed history of working practice records, and what it presently holds to be true about its operations are all the work of years and cannot be replicated by switching platform. That accumulated context is the one layer of the AI stack that is genuinely proprietary to each enterprise, and context data products are the architectural form in which it becomes usable.
The cost of this discipline is worth naming. Context data products add engineering work on top of a discipline that is already more expensive than leaving raw tables exposed. A table is cheap. A contracted data product is more expensive. A context data product with its semantic, temporal, usage, and confidence attributes fully specified is more expensive still.
For that reason, the architect must choose which data products earn the investment:
- An asset that is already being consumed by agents, or that is intended to be, belongs on the roadmap.
- An asset whose regulatory exposure rewards traceability belongs on the roadmap.
- An asset whose use crosses multiple domains and therefore depends on reconciled meaning belongs on the roadmap.
- An asset whose semantic drift is already producing visible failures belongs on the roadmap.
- Other assets can remain raw exposures without damaging the architecture, provided they are not consumed by anything that demands semantic guarantees.
As with capabilities in earlier chapters, the Codex works because it is selective, and the context data product layer should be selective in the same spirit.
10. MCP as the distribution protocol
Specifications, contracts, semantic layers, and context are valuable only to the extent that they reach the consumer. For agentic consumers, the distribution protocol that has consolidated in 2025 and 2026 is the Model Context Protocol.
Introduced by Anthropic in November twenty-twenty-four and donated to the Linux Foundation’s Agentic AI Foundation in December 2025, MCP has become the de facto standard for how AI agents discover, authenticate with, and invoke enterprise tools and data sources, adopted by major vendors across the model, cloud, and middleware tiers, with Gartner projecting that most API gateway and iPaaS vendors will expose MCP features through 2026.
The architectural consequence for data management is direct. A data product with a well-defined contract and a semantic binding becomes discoverable and usable by any MCP-compliant agent when it is exposed through an MCP server, so the MCP output port declared in the data product descriptor above becomes the basis for a generated MCP server that advertises the product’s tools, data endpoints, and semantic context to connecting agents. The agent does not need a bespoke integration; it needs only the protocol.
This changes where the integration investment happens.
- In the pre-MCP world, integration was an M times N problem, in which every agent vendor built a connector for every enterprise system or the enterprise built an adapter for every agent vendor, and the work scaled badly.
- With MCP, the integration becomes M plus N: the enterprise exposes its data products and tools through MCP servers once, and any compliant agent consumes them.
The specification-driven approach aligns naturally with this model because the data product specification, the contract, and the semantic binding together contain everything an MCP server generator needs.
What MCP does not do is solve the semantic interpretation problem. An MCP server that exposes a poorly specified data product still exposes a poorly specified data product, and an agent that consumes such a product will still hallucinate. The role of MCP is distribution rather than meaning, and the specification work developed in earlier sections remains necessary regardless of the protocol. What MCP contributes is that the architecture team no longer has to design and maintain a proprietary consumption layer for each new generation of agent tooling: the protocol is stable enough to invest behind, and the specifications the enterprise produces through the Codex are the payload that MCP carries.
11. ACME Pharma: site activation as a context data product
The example that ties the preceding specifications together is the site activation context data product at ACME Pharma, following the same enterprise scenario used in earlier chapters.
Site activation is a natural candidate for this treatment because it crosses organizational boundaries between clinical operations, regulatory affairs, and quality, carries regulatory exposure as the activation record is evidence in inspections and submissions, is queried by both humans and agents including the protocol assistant agent introduced in an earlier chapter, and has historically suffered from semantic drift because different country organizations have interpreted activation status differently.
- The business object declared in Section 4 anchors the enterprise meaning.
- Site activation is an event with a canonical identifier, a status from a closed vocabulary, an effective date, a regulatory evidence reference, and an invariant requiring regulatory approval evidence, bound to the clinical operations ontology under version 2026.1.
- The data product descriptor packages the realization with three output ports (snapshot, event stream, and MCP), quality commitments declared and made executable, ontology and knowledge graph binding, lifecycle metadata, and a high portfolio priority reflecting its multi-capability dependencies.
- The contract defines the schema field by field, binds each field to an ontology term, states quality rules with SLA thresholds, expresses access control as an OPA policy reference, declares service levels, and records the lineage to upstream systems.
- The context extensions are what make this a context data product rather than a well-specified conventional one. Every record carries temporal attributes, including the effective date from the source event, the snapshot generation timestamp, and the latest-as-of marker for freshness, along with a confidence score computed from source completeness and quality-rule compliance at generation time. The product also registers usage patterns through the catalog, so the knowledge graph can expose examples of successful queries and known pitfalls, and the ontology binding allows the semantic layer to resolve questions such as “which sites in Japan are activated but not yet recruiting” without the agent parsing column names.
The behavior when the protocol assistant agent receives that question is instructive.
- The agent begins by consulting the MCP endpoint of the site activation data product, which advertises the product’s contract and its semantic binding.
- Through that binding the agent resolves the definition of activation status against the clinical operations ontology and the jurisdiction attribute for Japan against the structural ontology’s mapping of country codes.
- It then retrieves the matching records, each of which arrives with its confidence score and freshness attributes attached.
- The answer the agent constructs therefore cites not only the record set but the effective-as-of timestamp and the confidence range.
- Where the confidence on a record fall below a threshold declared in the context specification, the agent flags that record for review rather than including it unconditionally.
- A compliance officer reviewing the output can follow an auditable chain from the question back through data product, contract, and business object to the governing decisions and invariants in the Codex.
Before the context data product existed, the same question produced different answers from different sources: the clinical operations reporting service counted conditionally activated sites as activated for operational reasons while the regulatory affairs dashboard excluded them, and the protocol assistant agent, drawing from whichever source it connected to, answered confidently and sometimes incorrectly. Resolution was a sequence of meetings, a shared spreadsheet, and an informal guidance note that faded from memory within a year. The context data product encodes the resolution as a specification, so the next time the question is asked the answer is consistent because the specification is the source.
12. What this changes for architects
The architect’s role expands rather than contracts when data is brought into the spec-driven frame.
- Data portfolio governance moves from the data management function into shared stewardship with enterprise architecture, because the business object taxonomy, the data product catalog, the contract portfolio, and the semantic layer are architectural assets.
- The architect does not replace the data product owner, the data engineer, or the data governance lead.
- The architect owns the specification surface across which these roles coordinate and the conformance rules that make the surface coherent.
Concretely, the review surface of enterprise architecture widens to accommodate the data artifacts.
- A business object proposal lands on the EA council’s agenda for the same reasons an intent or capability proposal would.
- The data product portfolio is treated with the same portfolio discipline the application estate already receives, because otherwise the number of products drifts upward and the duplication the mesh was meant to avoid reappears in a new shape.
- Data contracts reach production only after conformance checks against enterprise policies have run, which means the contract review is a gating activity rather than a form of documentation.
- The ontology itself becomes a governed artifact: new classes are ratified through a process that guards against semantic fragmentation, and retired classes are deprecated rather than quietly removed. The semantic layer must have a declared architectural interface, tested in continuous integration, so that teams integrate against a contract rather than against the current state of someone else’s tool.
The architect’s skill profile shifts accordingly. Semantic modeling and policy expression both become working competencies rather than academic curiosities, because contract enforcement relies on Rego, SodaCL, or similar policy languages, and the data platform has become the enforcement point for the specifications architecture produces. Platform engineering literacy is therefore essential: the architect who cannot read a data contract or reason about an ontology binding will be unable to govern data in the spec-driven frame, just as the architect who cannot read a Kubernetes manifest is unable to govern platform decisions.
A second consequence is that the boundary between enterprise architecture and data governance becomes less crisp than most organizations have drawn it.
- Traditional data governance produced policies, stewarded glossaries, and ran quality programs as a function parallel to architecture. In the spec-driven frame those activities stop being a parallel function.
- A glossary term is a semantic mapping on a business object, and the business object sits in the Codex. Stewardship is the change authority on that object.
- Quality programs are the operational reading of the contract’s quality rules. None of this eliminates the data governance function, but the function’s relationship to architecture moves from adjacent to integrated.
Enterprises that currently run separate EA councils and data governance councils will, over time, find the two converging on the same artifacts, and the governance model should plan for that convergence rather than resist it.
13. Risks, limits, and trade-offs
Semantic modeling overhead can consume more effort than it returns if applied uniformly across the data estate. Not every table deserves a business object, and not every data product deserves an ontology binding. The selectivity that worked for capabilities in earlier chapters applies here. The Codex does not carry every piece of enterprise knowledge; the business object catalog does not carry every data element; the context data product pattern is reserved for the assets where cross-domain reasoning, regulatory exposure, or agentic consumption actually justify the cost. An enterprise that attempts to semantically govern every asset will burn out its modeling capacity and produce artifacts that drift within a year.
Ontology drift is the most insidious risk, because it is rarely visible until an agent answers a question incorrectly. When multiple domains extend the ontology independently, subtle inconsistencies accumulate. A clinical operations team may model an activation event as an instantaneous transition while a regulatory affairs team models it as a process with a duration. Both are locally right. The knowledge graph built over both produces answers that look coherent and are silently wrong. Governance for ontology evolution must therefore include explicit cross-domain review whenever classes are reused, and the change authority for shared classes must sit above the domain level.
Context data products also cost more to build than raw data or conventional data products. The additional engineering work is real: quality machinery must be instrumented, semantic bindings must be maintained, context attributes must be computed at generation time, and the product must be made addressable by the knowledge graph and the MCP layer. An enterprise that commits to this pattern without a prioritization model will consume its data platform team’s capacity on a handful of products and leave the rest unimproved. The prioritization model itself should be explicit and auditable. Which data products are on the context roadmap, which remain conventional, and which stay as raw exposures should be architectural decisions recorded in the Codex, not an accumulation of unplanned choices.
MCP is a standard, but a standard does not enforce meaning. An MCP server that exposes a poorly specified data product exposes a poorly specified data product at higher velocity. The temptation to treat MCP as a shortcut to agentic readiness should be resisted, because the specification work developed in earlier sections is the precondition for safe MCP exposure. Exposing an unspecified data product through MCP is worse than not exposing it at all, because the exposure invites agents to reason over the product and reproduces, at scale, the hallucination patterns the spec-driven frame was designed to eliminate.
The counter argument that deserves direct acknowledgment is that this approach is data mesh with ontology and AI branding. The objection is partly fair, because the individual ideas (domain-oriented ownership, data as a product, contracts, semantic layers) are not new. The contribution of the spec-driven frame is not the invention of these ideas but their coordination under a shared specification discipline tied to the Codex, the decision log, and the control plane.
- Adopting data products without contract discipline produces labeled tables rather than governance.
- Adopting contracts without semantic discipline produces valid garbage.
- Adopting ontologies without product ownership produces academic models that no operational pipeline consumes.
The architectural value is in the integration. And even the best integration does not replace the social negotiation over meaning that two disagreeing finance teams still need to conduct; the Codex is where the reconciliation is recorded, not where it is achieved.
14. Conclusion
Data is one of the three domains enterprise architecture has always claimed to govern, alongside applications and infrastructure. If specification-driven thinking does not reach data, the architecture governs nothing an AI agent can safely consume, and the argument the earlier chapters developed remains incomplete in its most consequential direction.
The same chain that carried intent into capability, decision, specification, control, and delivery must carry semantics into operational form. In this chapter that carrying happens through:
- the business object as the semantic commitment held in the Codex,
- the data product as the unit in which the commitment is realized,
- the data contract as the commitment made enforceable,
- the semantic layer as the surface through which the enforced commitment reaches the consumer.
The context data product is what allows that consumer, when it is an agent, to answer with something other than a plausible guess.
The transition this requires is a discipline, not a procurement decision. The standards exist:
- The Open Data Product Specification and the Open Data Contract Standard cover the open side.
- Palantir, Atlan, Sema4.ai, and Timbr cover the platform side.
None of them, on its own, produces the discipline. The discipline is produced when the architecture team writes business object specifications, data product descriptors, data contracts, and ontology bindings as Codex artifacts, and when the delivery platform enforces them continuously. Where that happens, an agent connected through MCP to a context data product can answer a regulated business question with an auditable chain from answer back to specification, and the architecture has done what it exists to do.
15. Sources
- Ademola, Rotimi, Context Data Products as real differentiators in the AI era. Formulation of context data products and the four context dimensions. https://medium.com/@arrufus/context-data-products-as-real-differentiators-in-the-ai-era-1664c951bac3
- Open Data Product Specification 4.1, Linux Foundation. Vendor-neutral machine-readable data product metadata model with product strategy and portfolio priority. https://opendataproducts.org/v4.1/
- Open Data Mesh, Data Product Descriptor Specification. Declarative data product definition with interface and internal components. https://dpds.opendatamesh.org/
- Data Contract Specification, datacontract.com. OpenAPI-style specification for data contracts and reference tooling. https://datacontract.com/
- Soda, The Definitive Guide to Data Contracts. Executable contract patterns and git-managed workflow. https://soda.io/blog/guide-to-data-contracts
- Palantir, Ontology Overview. Operational digital twin and semantic layer built on the Foundry ontology. https://www.palantir.com/docs/foundry/ontology/overview
- Salesforce Architects, The Agentic Enterprise: IT Architecture for the AI-Powered Future. Semantic layer as a tier above the data layer, with structural and descriptive ontology distinction. https://architect.salesforce.com/fundamentals/agentic-enterprise-it-architecture
- Atlan, What Is Ontology in AI. Ontology-first architecture compared with schema-first and prompt-first approaches. https://atlan.com/know/what-is-ontology-in-ai/
- Enterprise Knowledge, Injecting Business Context into Structured Data Using a Semantic Layer. Semantic assets and their role in enterprise AI architecture. https://enterprise-knowledge.com/enterprise-ai-architecture-inject-business-context-into-structured-data-semantic-layer/
- TOGAF Series Guide, Information Mapping. The business object and information concept relationship in the TOGAF and ArchiMate frame. https://pubs.opengroup.org/togaf-standard/business-architecture/information-mapping.html
- Anthropic, Introducing the Model Context Protocol. Protocol rationale and architecture. https://www.anthropic.com/news/model-context-protocol
- Model Context Protocol, official site. Protocol specification and client and server overview. https://modelcontextprotocol.io/
- Dehghani, Zhamak, Data Mesh principles. Domain ownership, data as a product, self-serve platform, federated computational governance. Accessed through the Open Data Mesh reference. https://dpds.opendatamesh.org/concepts/data-product/
- Gartner, Top Predictions for Data and Analytics in 2026. Governance and interoperability projections for AI agent deployment. https://www.gartner.com/en/newsroom/press-releases/2026-03-11-gartner-announces-top-predictions-for-data-and-analytics-in-2026
- Atlan, Gartner D&A Summit 2026: Key Takeaways on Context and AI. Summit framing of context layers as critical AI infrastructure and MCP-plus-semantic-layer guidance. https://atlan.com/know/gartner/key-takeaways-from-gartner-da-summit-2026/
- Google Cloud, Welcome to Google Cloud Next '26. Knowledge Catalog as part of the Agentic Data Cloud and bidirectional catalog federation to SAP, ServiceNow, Salesforce, and Workday. https://cloud.google.com/blog/topics/google-cloud-next/welcome-to-google-cloud-next26
- Apache Iceberg, project documentation. Open table format for analytic datasets, referenced as the de facto cross-engine standard for cross-cloud lakehouse architectures. https://iceberg.apache.org/
- Regulation (EU) 2016/679, General Data Protection Regulation (GDPR). Cross-border transfer rules underpinning sovereignty constraints in DATA-006. https://eur-lex.europa.eu/eli/reg/2016/679/oj
- Court of Justice of the European Union, Case C-311/18 (Schrems II), 16 July 2020. Invalidation of the EU–US Privacy Shield and standard for cross-border data transfer adequacy. https://curia.europa.eu/juris/liste.jsf?num=C-311/18
- Regulation (EU) 2024/1689, Artificial Intelligence Act. Risk-tiered obligations for AI systems, referenced as a constraint on agent contracts and data residency. https://eur-lex.europa.eu/eli/reg/2024/1689/oj
- U.S. Department of Health and Human Services, Health Insurance Portability and Accountability Act (HIPAA). Sectoral privacy framework for protected health information. https://www.hhs.gov/hipaa/index.html
- Standing Committee of the National People's Congress, Personal Information Protection Law of the People's Republic of China (PIPL). Cross-border transfer rules and consent requirements. http://en.npc.gov.cn.cdurl.cn/2021-12/29/c_694559.htm
- Ministry of Electronics and Information Technology, India, Digital Personal Data Protection Act, 2023 (DPDP). Personal data processing and cross-border transfer regime. https://www.meity.gov.in/data-protection-framework
- ICH Harmonised Tripartite Guideline E2A, Clinical Safety Data Management: Definitions and Standards for Expedited Reporting. Source for the adverse-event canonical definition in the SCC-PV-001 conformance check. https://database.ich.org/sites/default/files/E2A_Guideline.pdf
- European Medicines Agency, Guideline on Good Pharmacovigilance Practices (GVP) Module VI. Adverse-reaction reporting framework cited in the conformance-check approved definition. https://www.ema.europa.eu/en/human-regulatory-overview/post-authorisation/pharmacovigilance-post-authorisation/good-pharmacovigilance-practices
- U.S. Food and Drug Administration, 21 CFR 314.80, Postmarketing Reporting of Adverse Drug Experiences. Regulatory anchor for the adverse-event definition in the SCC example. https://www.ecfr.gov/current/title-21/chapter-I/subchapter-D/part-314/subpart-B/section-314.80